1. 文章简介
1.1 摘要
基准测试和协同设计对于推动 ML 模型、ML 软件和下一代硬件的优化和创新至关重要。全工作量基准(如 MLPerf)在实现不同软件和硬件堆栈之间的公平比较方面发挥着至关重要的作用,尤其是在系统完全设计和部署之后。然而,人工智能创新的步伐要求模拟器和仿真器采用更加敏捷的方法来创建和使用基准,以实现未来的系统协同设计。我们提出了 Chakra,这是一种开放式图模式,用于标准化工作负载规范,捕捉关键操作和依赖关系,也称为执行跟踪(ET)。此外,我们还提出了一套互补的工具/功能,使各种模拟器、仿真器和基准能够收集、生成和采用 Chakra ET。例如,我们使用生成式人工智能模型学习数千种 Chakra ET 的潜在统计属性,并使用这些模型合成 Chakra ET。这些合成的 ET 可以混淆关键的专有信息,还可以针对未来的假设场景进行设计。举例来说,我们展示了一个端到端的概念验证,它能将 PyTorch ET 转换为 Chakra ET,并以此驱动一个开源训练系统模拟器(ASTRA-sim)。我们的最终目标是建立一个充满活力的全行业敏捷基准和工具生态系统,以推动未来的人工智能系统协同设计。
1.2 研究动机
Full Workload Benchmarks对于评价分布式训练的性能虽然非常重要,但是需要更加敏捷的方式
评价分布式训练的软硬件联合设计的效果
不同的AI/ML模型通常由不同的公司在不同的平台上构建,通常不能提供公开模型的细节
缺少在不同的组织之间交换ML模型ET的统一架构
缺少完善的性能评估工具链
目前的方法缺乏合成ET的能力
以Pytorch为例,可以使用Execution Graph Observer获取直接的ET,但是这种方法得到的结果受真实的系统的限制(例如NPU数量,计算时间,网络延迟等),使用合成的ET可以避免这些限制
1.3 主要贡献
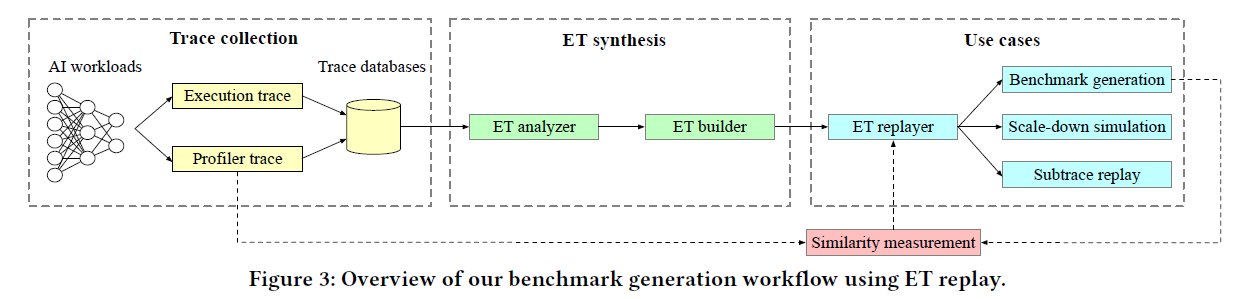
捕捉相关执行和依赖信息的 Chakra ET
可视化器、转换器和模拟器等开源工具链
人工智能生成模型的ET合成
2. 实现方法
2.1 设计需求
应该包含内存访问、计算负载、网络通信、并行策略
应该最小化且可扩展
应该从性能建模的角度对 ML 执行的各个方面进行建模
应该能显示不同执行阶段的ET,且与设备解耦
2.2 实现方案
2.2.1 ET的表示
A. Chakra Node

type的值范围
INVALID 字段的初始值,用于忽略非关键节点
MEM_LOAD、MEM_STORE
COMP
COMM_SEND、COMM_RECV、COMM_COLL
B. Chakra Attribute
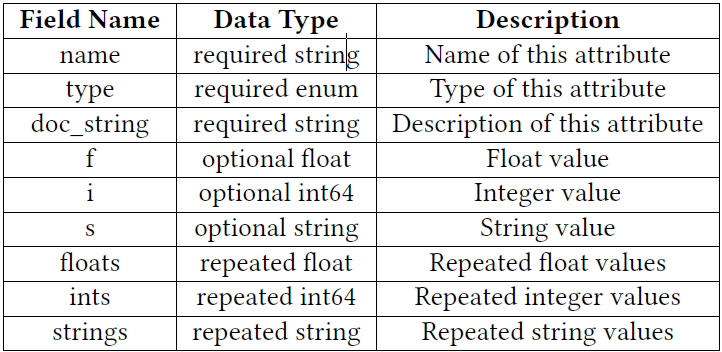
type的值范围
6种:float, int, string, and their repetitions
2.2.2 ET的收集
Pre-Execution vs. Post-Execution 确定适当的跟踪收集级别是一项关键的设计选择。一般来说,跟踪收集级别可分为执行前和执行后两种。
Pre-Execution是指ML模型尚未明确优化或与特定系统配置(如引擎、内存或网络)绑定的阶段
Pre-Execution段收集跟踪,可以对不同系统的性能进行预测,因为它与特定配置无关
Post-Execution阶段涉及在实际系统上优化和执行 ML 模型
Post-Execution阶段收集的ET与运行模型的实际系统紧密相关,在性能预测方面的实用性受限制
Chakra 模式旨在适应任何执行阶段。然而,如何从真实系统中收集迹线而不与之紧密绑定仍是一个未决问题。
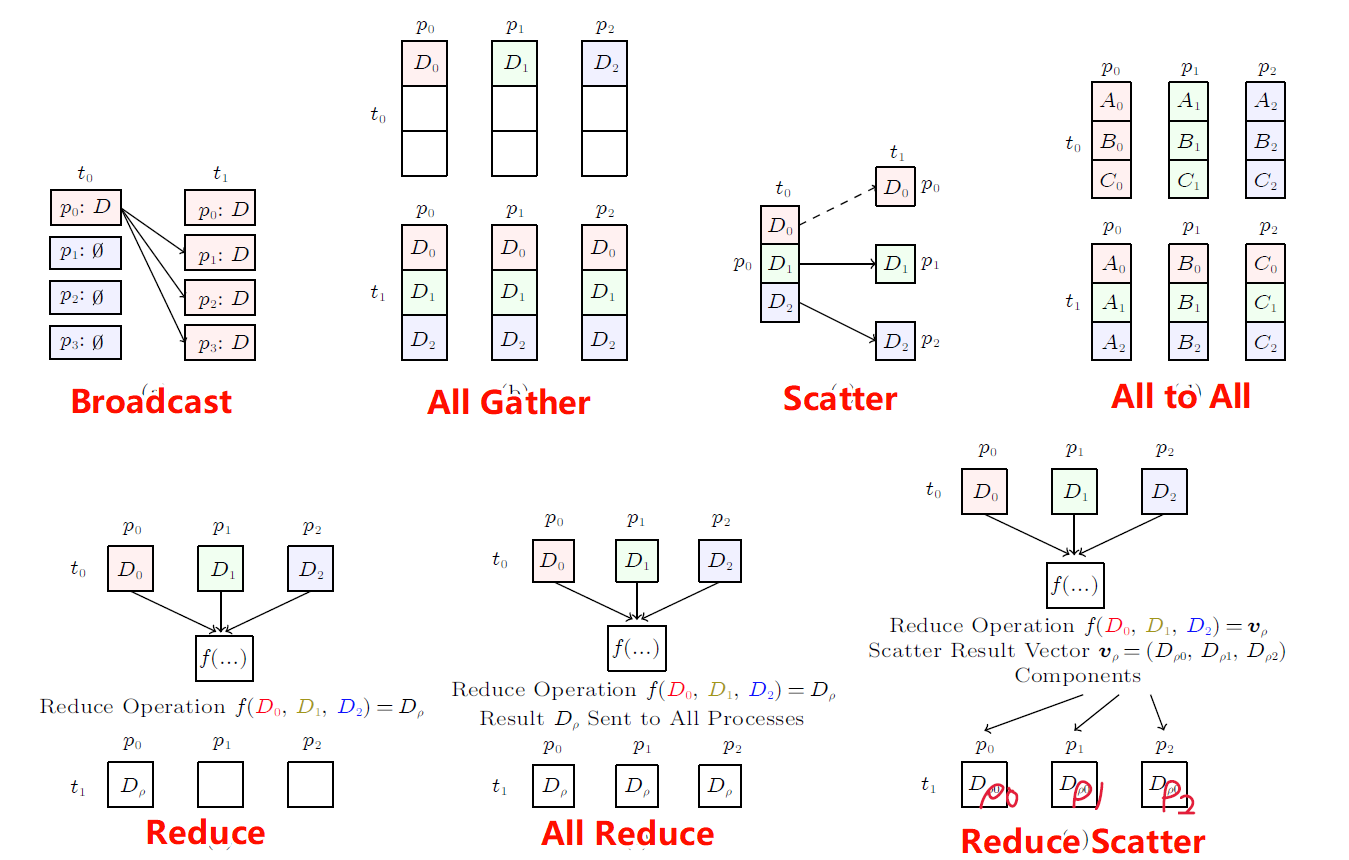
支持按照分布式策略分解成多个ET,并部署到多个NPU上执行
也可以支持从多个分布式的ET文件合并成一个单个的Master Trace,这个过程是无损可逆的
在收集ET时,由于不同的框架具有不同的ET格式,因此可以使用ET转换脚本转为标准的ET格式
3. 实验结果
实验条件
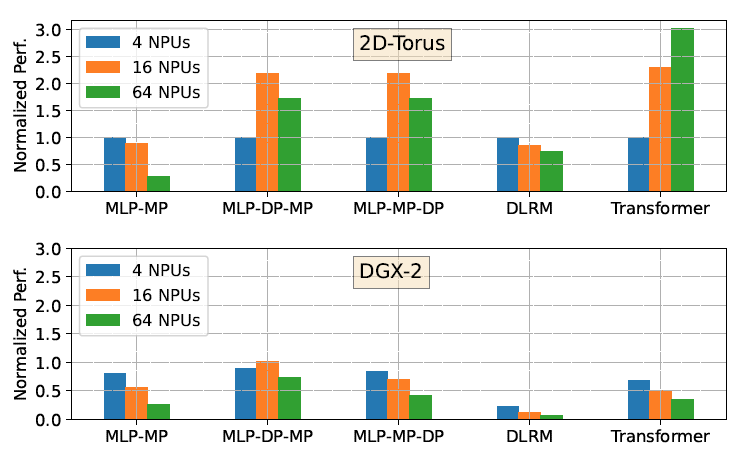
The 2D-torus is an 8×8 2D-torus topology with 64 NPUs and a link bandwidth of 62GB/s.
the DGX2 is a hierarchical network topology connected with switches, with network bandwidths for the first and second dimensions set to 600GB/s and 37.5GB/s
不同模型和并行数量的仿真结果
et.al.
4. 其他内容
假定存在一个使用Pytorch编写的ML代码,生成ET的步骤如下:
在PyTorch中启用Execution Graph Observer,这是一个用于收集模型执行时的详细信息的工具。它不需要对ML模型进行侵入性修改。
运行PyTorch模型进行训练。在训练过程中,Execution Graph Observer将捕获关键的操作和依赖关系,生成原始的执行跟踪数据。
将PyTorch生成的原始执行跟踪转换为Chakra ET格式。这可能涉及到使用ET转换器(ET Converter),它能够读取PyTorch的JSON格式跟踪数据,并将其转换成Chakra定义的标准化ET格式。
利用Chakra提供的工具链,如执行跟踪可视化器(Execution Trace Visualizer)和时间线可视化器(Timeline Visualizer),来分析和理解ET。
使用收集到的Chakra ETs作为训练数据,训练一个生成性AI模型。这个模型将学习ETs中的统计特性和模式。
使用训练好的生成性AI模型来合成新的ETs。这些合成的ETs可以用于模拟不同的系统配置和未来场景,同时保护原始模型的知识产权。
将合成的ETs输入到性能模型或仿真器(如ASTRA-sim)中,以评估不同硬件配置下的性能。
分析仿真结果,识别性能瓶颈和优化机会。根据这些信息调整模型结构或系统配置,以提高性能。