Alibaba High Performance Network (HPN)
HPN介绍了一种两层的双平面网络,可以在一个Pod中接入1.5w个GPU,通常需要3层Clos架构的网络才能容纳这么多GPU
HPN 提出了一种新的双 ToR 设计,以取代传统数据中心网络中的单 ToR
1. 贡献与挑战
挑战
流量模式
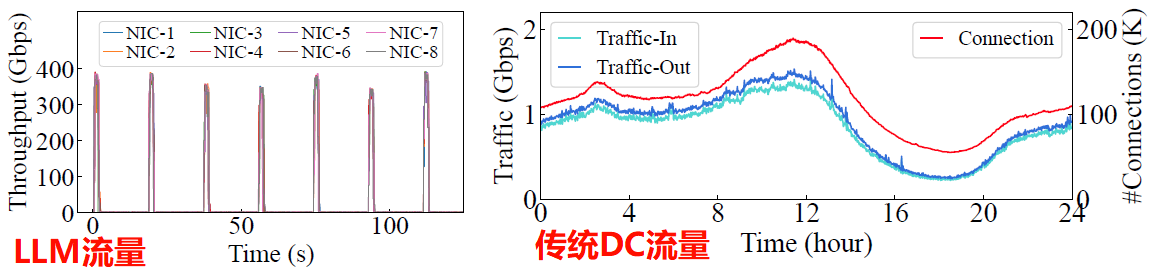
传统网络无法应对LLM的低熵、周期性、突发的网络特点,传统的数据中心网络一般是高熵的(传统网络中会存在百万条流,但是每条流的利用率特别低,一半小于20%)
ECMP在传统的数据中心的高熵、低利用率的网络中性能表现较好,但是在LLM训练中并不是最佳的
单点故障的敏感性高
LLM训练是一个同步过程,所有GPU合作完成一系列迭代,任何一个GPU发生故障都有可能导致整个训练过程出现问题
对LLM训练影响最大的是与机架顶部(ToR)相关的单点故障,这种故障可能会影响到各种GPU
生产统计数据显示,LLM训练中出现的故障造成的损失是一般云计算故障的 20 倍
贡献
非堆叠的双层ToR网络,可以在两个交换机之间直接同步,很好的改善了大规模部署的可信度
适配最新的51.2Tbps的交换机芯片,可以将1K个GPU部署在Tier 1网络中,使96.3%的训练任务获得高性能的网络
我们的实验表明,使用HPN的LLM训练吞吐量比传统数据中心网络高14.9倍
2. 背景知识
LLM的并行策略
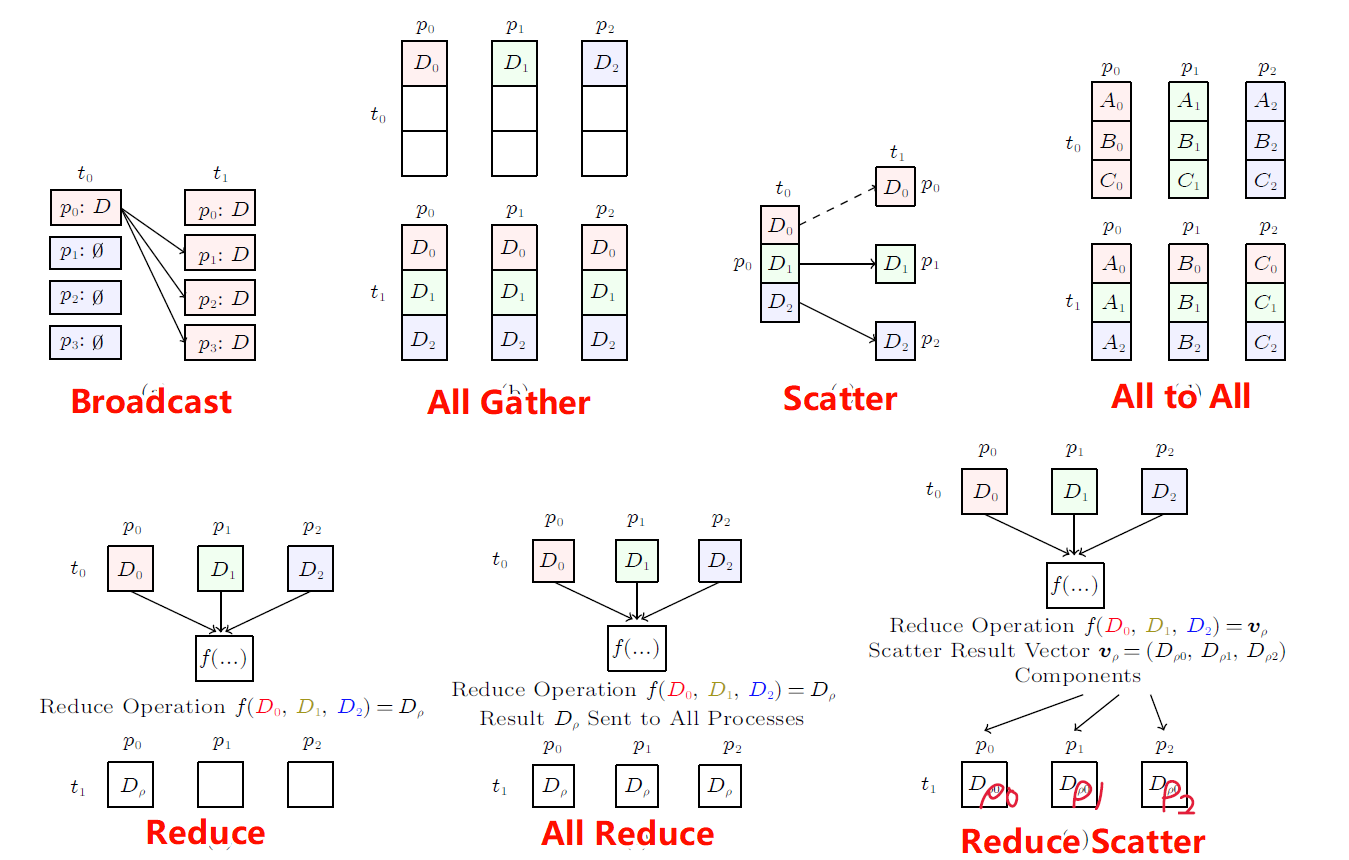
DP:每次迭代使用All Reduce同步计算梯度数据
PP:每次使用Send/Recv传递中间结果
TP:每次迭代使用All Reduce/All Gather同步输出和对应的梯度
LLM的流量特征
带宽利用率周期性突发
流的数量少
传统的数据中心网络不适用于LLM流量模式
LLM对单点故障的敏感性
LLM每次的Checkpoint间隔大概在2-4小时,按照一个3k张GPU的集群计算,每次失败导致的回滚都将导致大约3w美元的损失
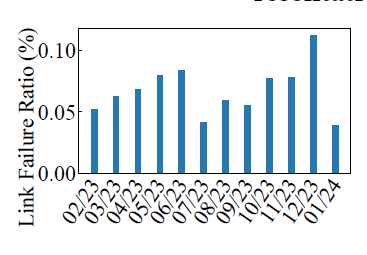
常见的监控工具和异常分析工具并不能避免网络产生故障,根据实验表明,在NIC到ToR之间每个月大概有0.057%的Link故障率,在ToR交换机每个月的故障率大约是0.051%,即一个LLM训练集群每个月可能会产生1-2次的Crash,5k-60k次的Link故障
LLM网络架构的建设目标
规模化:达到15K个GPU的规模,未来可以扩展到100K个GPU的规模
高性能:尽可能小的网络跳数,尽可能使用GPU-GPU直达的连接
单点故障容错率:在网络拓扑层尽可能改善单点故障的容错率
3. HPN架构
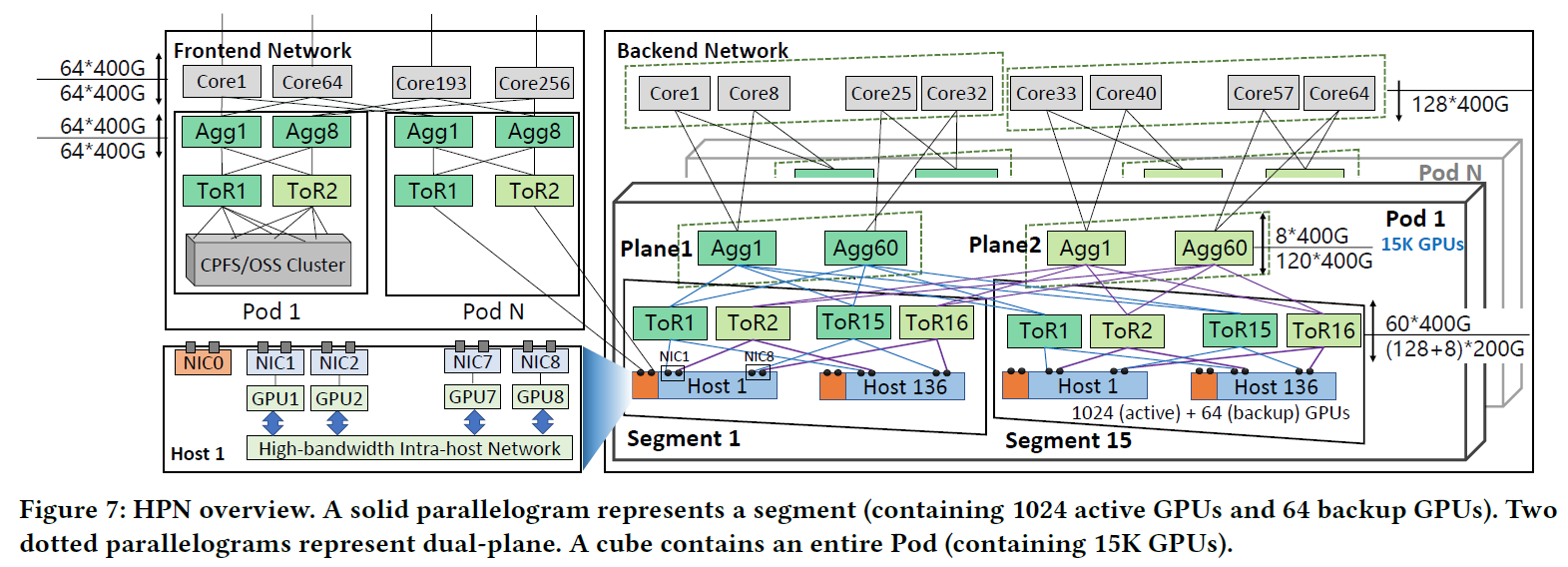
分为前端网络和后端网络,前端网络主要负责例如管理、接口、存储等网络流量,后端网络负责LLM的训练时的流量
每个Host包含8个GPU,使用NVLink互联,双向带宽达到400GBps-900GBps
每个Host包含9个2x200Gbps的网卡,其中一个连接到前端网络,其余的8个与GPU直连,接入后端网络
每个网卡的2个端口分别连接至不同的ToR网络,这种双ToR设计可以避免单点故障
4. 双ToR网络
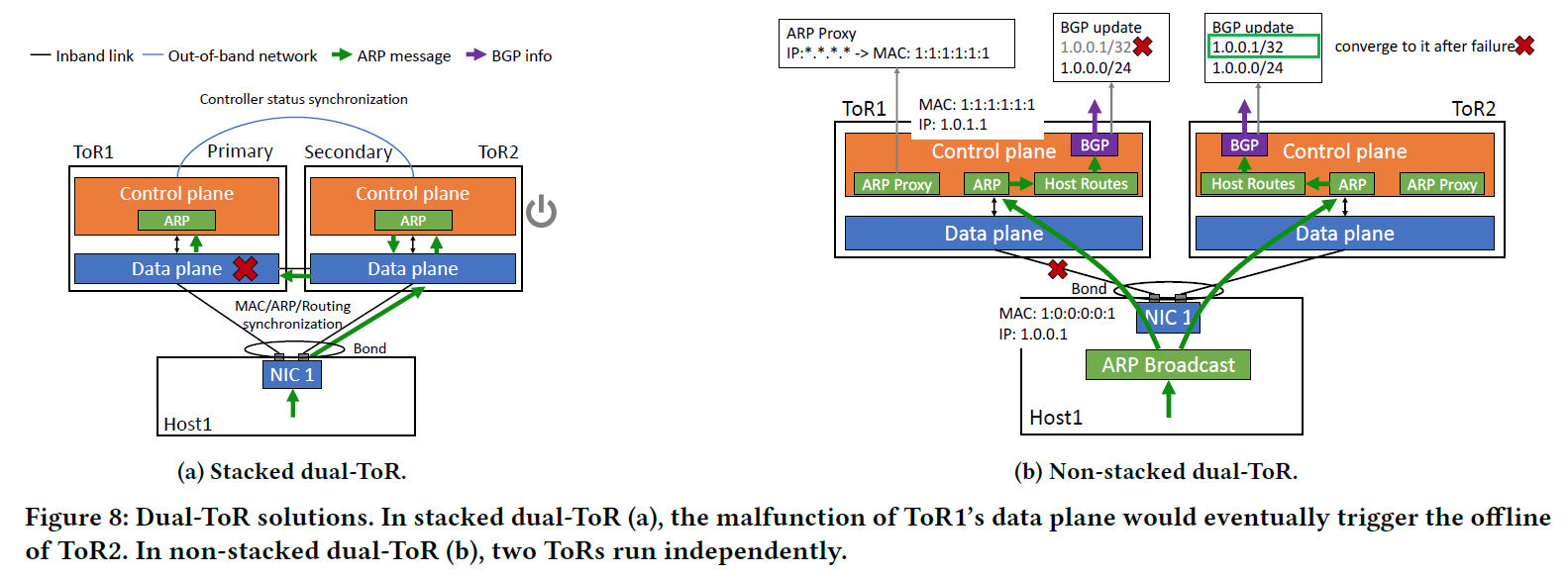
传统数据中心的NIC的两个光缆接入一个交换机成为单ToR设计
双ToR设计将NIC的两个光缆接口分别接入不同的ToR交换机中
两个接口配置相同的IP和MAC地址,即使其中一个ToR故障,另外一个依旧可以正常工作
基于以上,同一个NIC的两个网卡共享相同的Queue Pair Context
堆叠的双ToR
两个ToR之间强同步,当主ToR的数据平面发生异常但是控制平面正常时,数据流无法经过主ToR进行转发,此时主ToR的控制平面信息则会与副ToR的控制平面信息不一致,在主ToR看来,是副ToR发生异常导致了该不一致,因此主ToR并不会下线,在副ToR看来是主ToR发生了异常,因此但是主ToR并没有下线,因此副ToR无法切换为主ToR,系统为了避免这种不一致的ToR控制信息,副ToR只能被强制下线,由此整条通路都将会失效
非堆叠的双ToR
堆叠的双ToR失效的主要原因是两个ToR需要强同步。
两个ToR要设置为相同的MAC地址,同时要确保该MAC地址并没有被任何Host使用
不同的PortID,使用Offset计算出两个不同的PortID
5. Tier 1 Segment
在Tier 1,存在128+8个200Gbps的下游端口和60个400Gbps的上游端口,整个交换机的转发能力达到51.2Tbps,8个下游备用端口连接备用的Host
rail optimized network
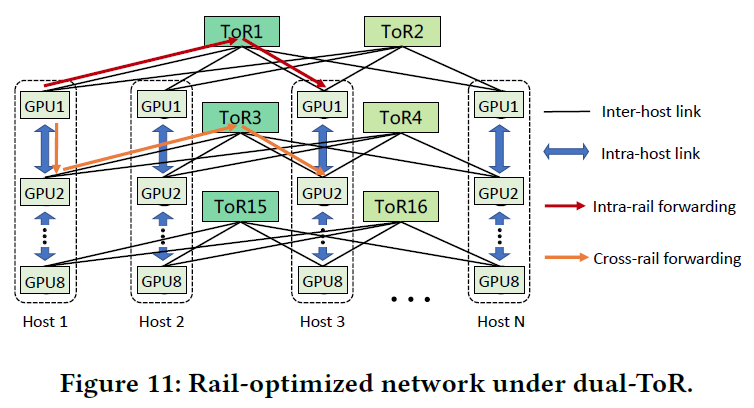
6. Tier 2 Pod
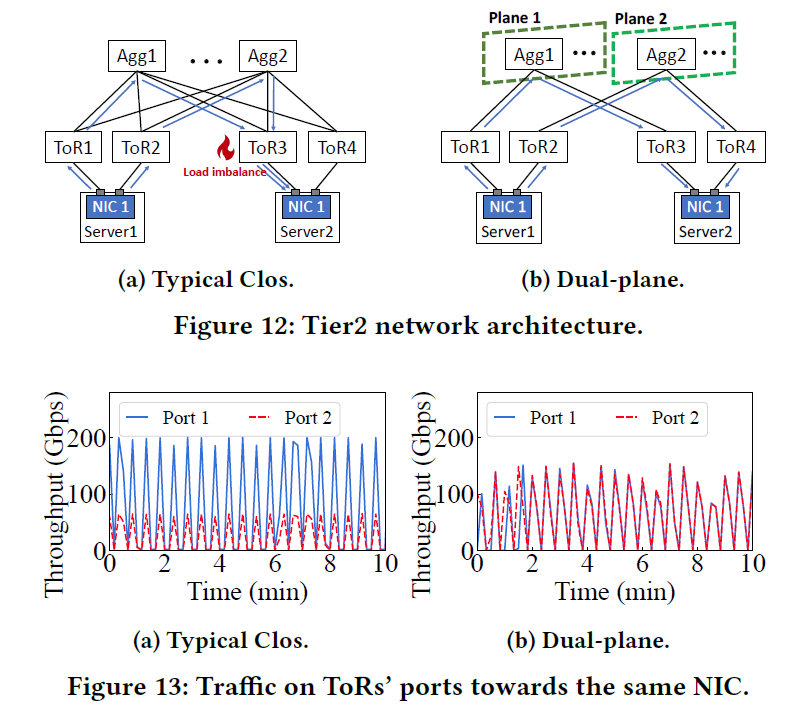
7. Tier 3 Larger Scale
以GPT-3 175B的训练为例,设置TP=8,PP=8,DP=512,使用32K 个GPU的条件下,流量分析如下:
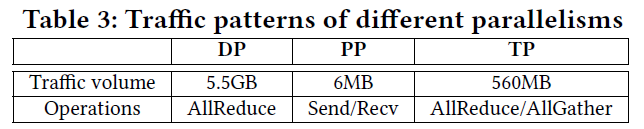
根据以上分析发现,PP的流量模式最小,因此可以将PP设置为跨Core层(Tier 3)的通信
8. 独立的前端网络
存储、关系等网络平面
9. 评估验证
HPN can improve the end-to-end large-scale training (taking up to 2300+ GPUs) performances by 14.9% compared with DCN+
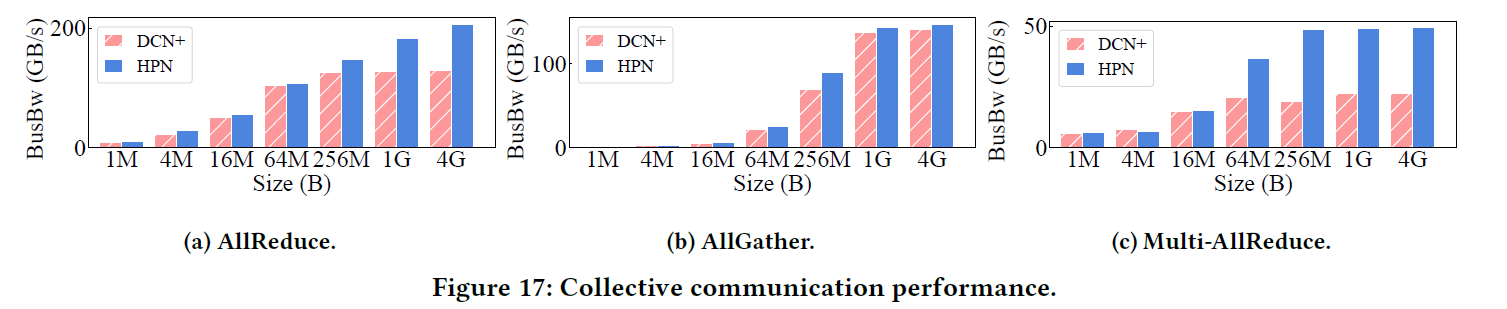
we conduct network layer monitoring and different collective communication operations to show HPN’s network layer performance improvement
网络层的性能
以下测试基于NCCL 2.18.3,使用56个Host(448个GPU)进行All Reduce/All Gather的测试
All Reduce性能增长59.3%,All Gather性能增长较小,可能是因为使用了NSLS导致数据可以在NVSwitch中进行聚合的原因