1. 挑战与贡献
挑战
模型的多样性和更新速度无法与云基础设施上不断变化、高度多样化的人工智能生产工作负载相匹配
工程师或研究人员需要手动选择现有的生产或开源工作负载,并将其调整为可用于基准测试的形式
贡献
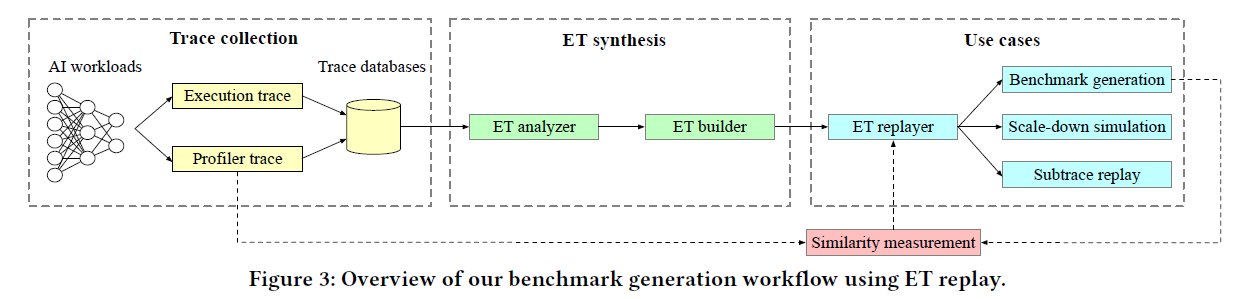
框架:建立了一个可扩展的自动化端到端基础设施,可对真实生产型人工智能工作负载的执行轨迹进行剖析和重现
高精度:通过在warehouse-scale fleet中运行的几个 PyTorch 生产工作负载对 Mystique 进行了评估,结果表明,生成的基准在性能和系统级指标方面与原始基准非常接近
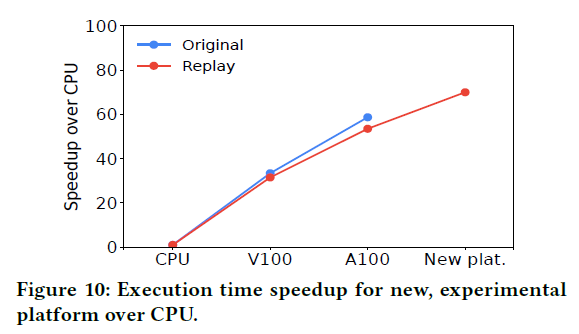
可移植性:展示了跨平台生成基准的可移植性,并评估了 Mystique 可应用的几种情况,包括早期平台评估、子轨迹重放和缩小性能测试
2. 相关工作
Benchmark
DeepBench:提供了一套深度神经网络(DNN)使用的基本操作,并在不同平台上对其进行了评估
TBD:确定了八个具有代表性的 DNN 模型,并在不同的深度学习框架和硬件配置上进行了详细的性能分析
DAWNBench:测量训练和推理的端到端性能,以规定的精度为前提,允许软件、算法、通信方法的创新
MLPerf:目前最为流行的Benchmark
仿真工具
Sniper:并行、可扩展的CPU仿真工具,对多核和多处理器进行高度抽象
gem5:一种微架构的仿真器,目前适用于仿真GPU
GPGPU-Sim:提供一种时钟周期级别的仿真工具,可以对运行CUDA和OpenCL的Nvidia GPU进行仿真
性能建模
Daydream:根据内核-任务依赖图预测模型在某些优化条件下的运行时间
Habitat:使用波形缩放和 MLP 预测 DNN 训练的执行时间
CM-DARE:提出了一种利用云端 GPU 服务器进行分布式训练的性能模型
性能收集
MicroGrad:收集CPU指标,并使用基于梯度下降的调整机制来生成工作负载克隆和压力测试
PerfProx:根据硬件性能计数器得出的性能指标,生成真实世界数据库应用程序的miniature proxies
CAMP:模拟核心性能、内存位置以及它们之间的相互作用,以模仿BigData应用程序
ECHO:重点是利用统计模型克隆分布式云应用中的网络行为,并生成与原始服务的定位和流量特征相似的合成基准
Ditto:提出了一种自动克隆框架,该框架可捕获分布式云应用程序的低级和高级性能指标
G-MAP:为 GPU 应用程序的内存访问模式和并行性建模,以创建内存代理
GPGPU-MiniBench:生成 CUDA GPGPU 内核的miniature proxies,以保持相似的性能
3. 相关背景
Pytorch
ATen ops:低层级的Tensor库,是Pytorch的后端,用于执行真实的计算任务(加法、矩阵乘法等)
Communication ops:多设备之间的分布式训练通信,通常为异步的。在Pytorch中c10d是一个非常流行的通信库,提供了大量的集合通信API和P2P通信API
Fused ops:融合操作,是一种计算加速优化方法,可以把多个操作融合成一个运算操作。CPU中常用NNC作为融合操作的后端,GPU中为NVFuser
Custom ops:允许用户实现比默认实现更好的模型块

4. Mystique设计
收集Trace
选择ops
ET收集的Trace中包含一些冗余信息,例如:aten::leaner()包含了aten::t()和aten::addmm()两个操作,但是在收集ET的Trace时,这三个操作都会被记录下来
重建ops
Aten ops
通过IR(Intermediate Representation)实现每一个ATen的算子重建,基于字符串解析的方法构建,最后用TorchScript对IR进行编译,为每个操作符创建可调用函数
Communication ops
为了重现原始工作负载的通信模式,我们需要重放通信操作符及其原始参数,如进程组和消息大小
Custom ops
输入输出信息可以被ET收集到,但是无法对此进行重建,因为我们无法获取它的具体实现,因此我们保留了一个接口,用户可以自定义实现这些运算
Fused ops
当前不支持这些操作,重现时将会跳过,因为它的占比不大,不过未来计划实现它
管理Args
中间张量:用于计算最终结果的一些中间变量,在它生成的时候保存它,并将其传递给下游的操作以便于构成中间的数据依赖
外部张量:输入输出的张量,在执行之前实例化
重现的时候使用相同的维度,但是内容使用随机数替代
并行Stream
大多数情况下,都会对计算和通信进行并行,以便于隐藏网络通信开销。通常,从Host到Device侧的数据传输也会优化成一个独立的Stream
在重现时需要识别出每条Stream所在的Kernel,每个Kernel上执行的操作,如此便可准备多条Stream并在重现时将指定的操作放置在指定的Stream上
问题:当前的ET不包含Stream信息,因此需要冲Pytorch Profiler处获取Stream信息(https://pytorch.org/tutorials/recipes/recipes/profiler_recipe.html)
5. 实现方法
以大概8000行代码实现,支持所有基础的ATen,大量的自定义运算符,少量的通用库(例如FBGEMM)和c10d分布式库,支持nccl,gloo,mpi,ucc等4种后端
允许用户在他们自己的代码中插入Hook(通常只需要20行左右)
6. 评估验证
测试环境:在10台A100或V100上进行验证,CUDA 11.4,Pytorch 1.14
测试负载:PARAM,ResNet,ASR,RM
测试范围
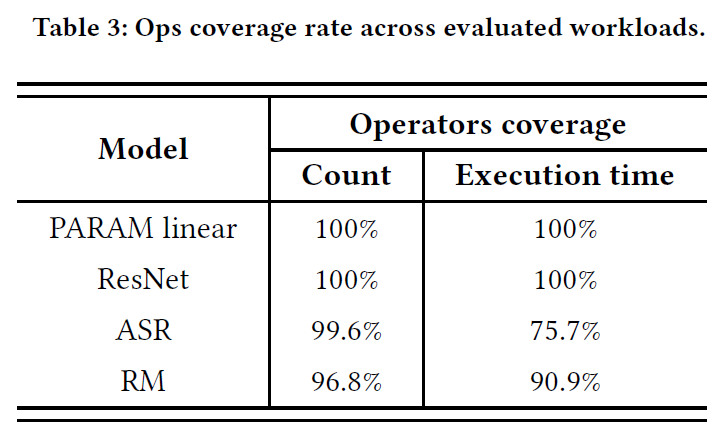
端对端的测试结果
执行Trace和重放Trace

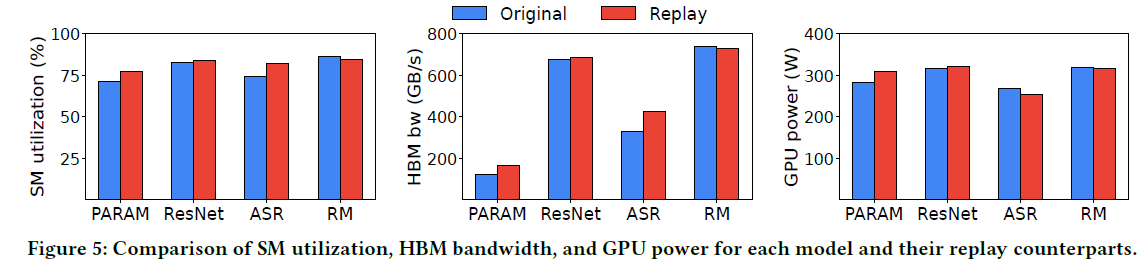
不同模型下的重放结果

对比SM利用率、HBM带宽和功耗等指标
新平台验证