文献阅读《Alibaba HPN: A Data Center Network for Large Language Model Training》
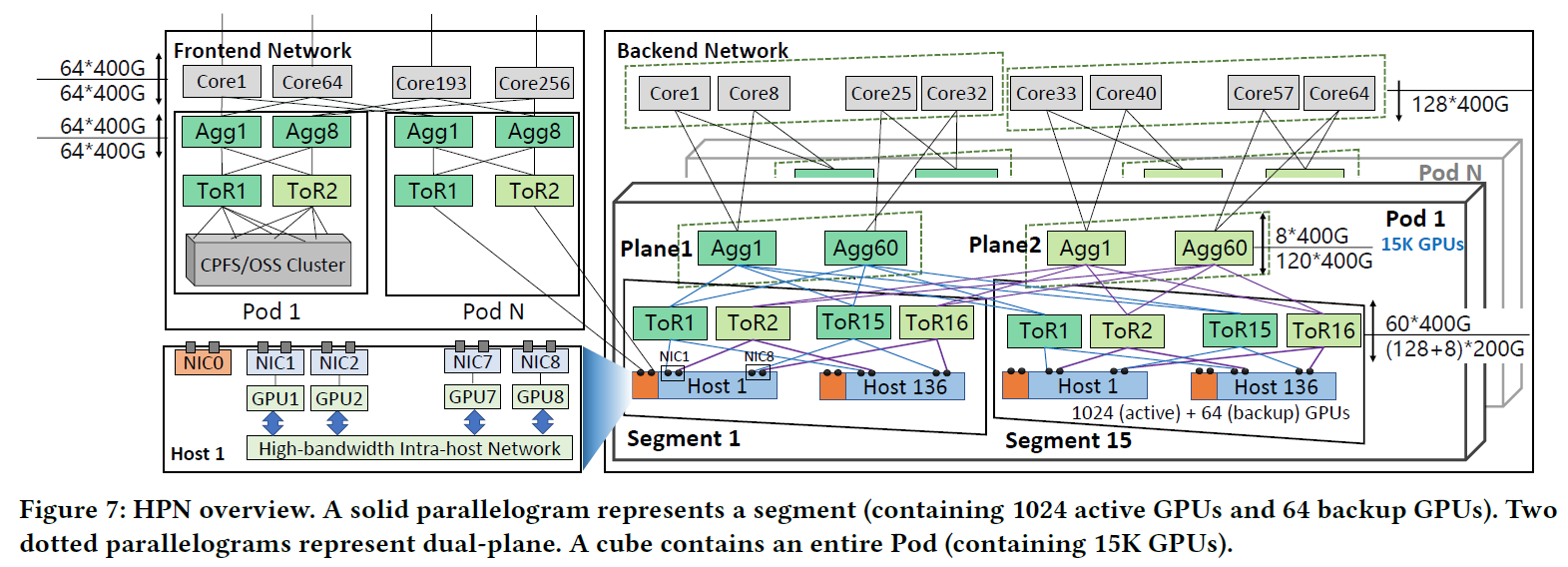
Alibaba High Performance Network (HPN) HPN介绍了一种两层的双平面网络,可以在一个Pod中接入1.5w个GPU,通常需要3层Clos架构的网络才能容纳这么多GPU HPN 提出了一种新的双 ToR 设计,以取代传统数据中心网络中的单 ToR 1. 贡献与挑战
文献阅读《xCCL: A Survey of Industry-Led Collective Communication Libraries for Deep Learning》
we survey the current state-of-the-art collective communication libraries (namely xCCL, including NCCL, oneCCL, RCCL, MSCCL, ACCL, and Gloo), with a f
文献阅读《Impact of RoCE congestion control policies on distributed training of dnns》
1. 内容简介 1.1 摘要 聚合以太网(RoCE)上的 RDMA 协议因其与传统以太网结构的兼容性而对数据中心网络产生了巨大的吸引力。然而,RDMA 协议只有在(几乎)无损网络上才有效,这就强调了拥塞控制在 RoCE 网络中的重要作用。遗憾的是,基于优先级流量控制(PFC)的本地 RoCE 拥塞控
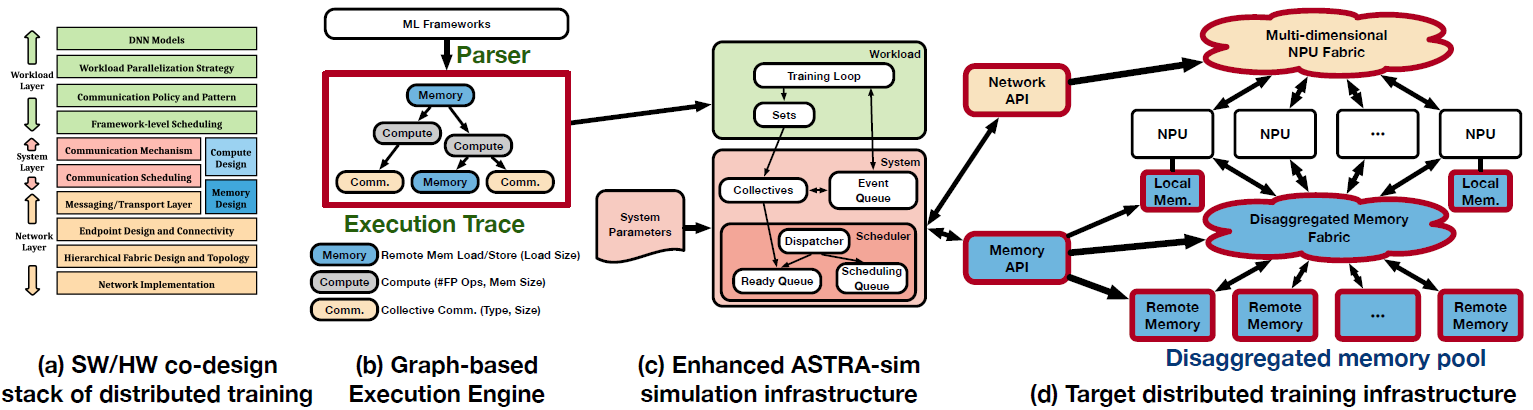
《ASTRA-sim 系列两篇》
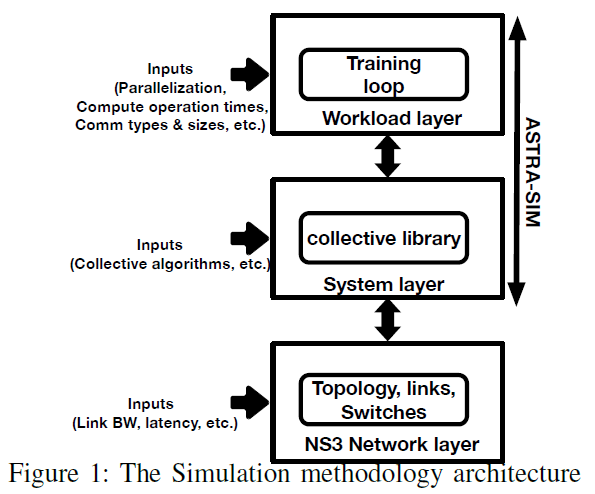
《ASTRA-SIM: Enabling SW/HW co-design exploration for distributed DL training platforms》 1. 文章简介 1.1 摘要 现代深度学习系统主要依靠基于高性能加速器(如 TPU、GPU)的硬件平台进行分布式训练。目前的
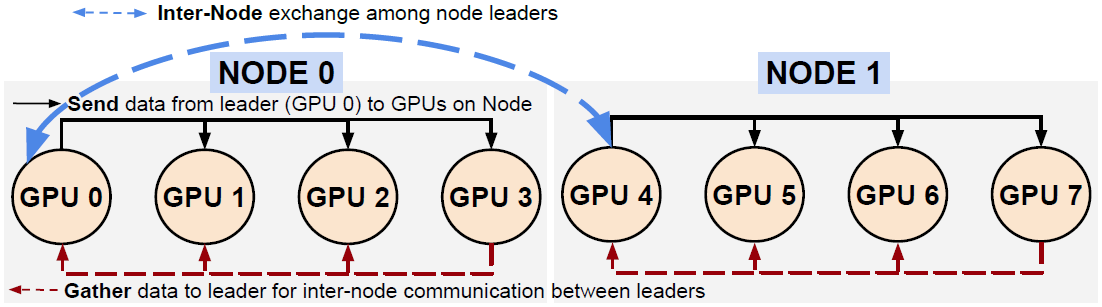
文献阅读《Adaptive and Hierarchical Large Message All-to-all Communication Algorithms...》
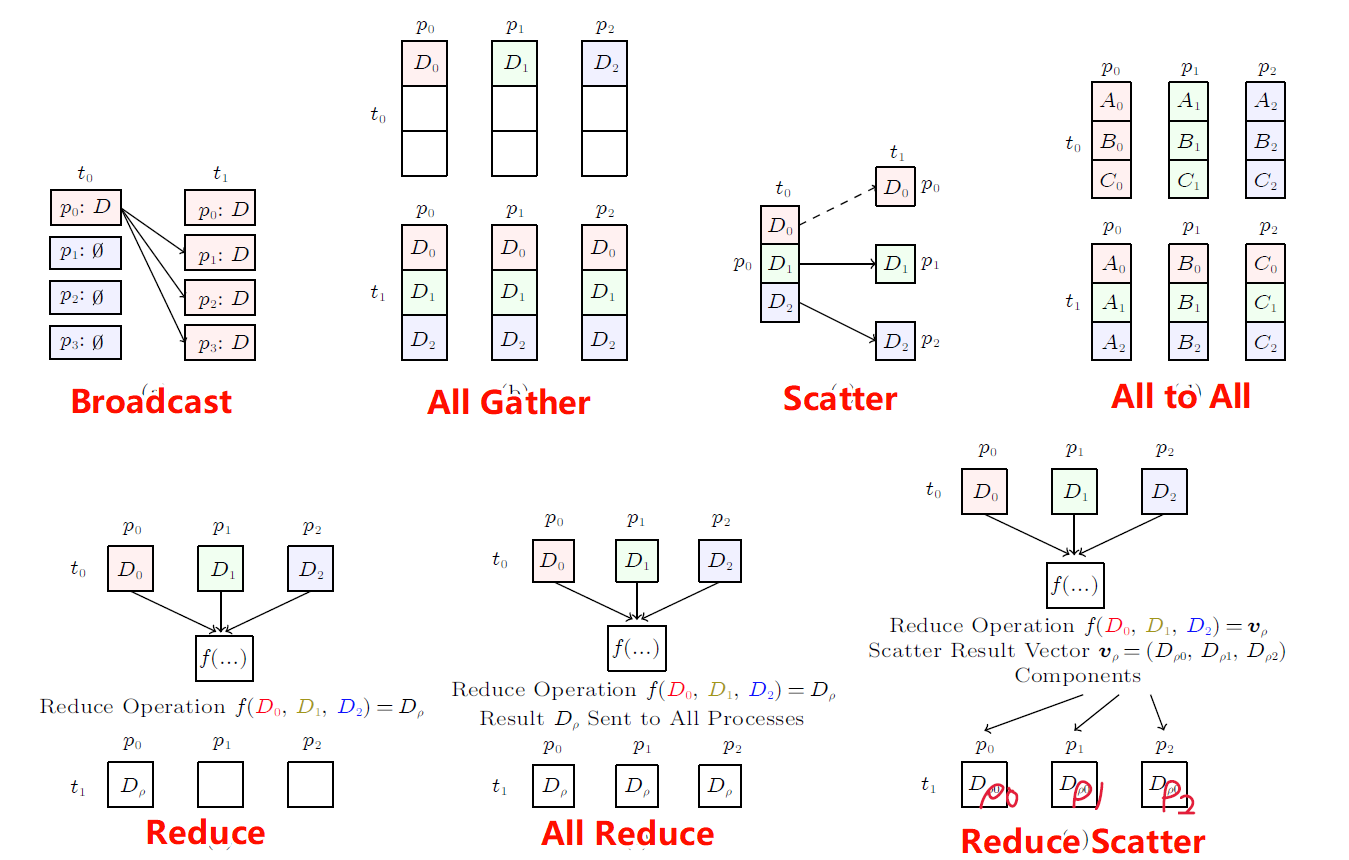
I. 前置内容 在了解集合通信(Collective Communication)之前要先了解点P2P对点通信(Point-to-Point)。P2P通信通常为两个不同进程间的通信,是1对1的; 在MPI规范中,既有同步阻塞的P2P接口:MPI_send和MPI_Recv接口,也定义了非阻塞的P2P
最新文章
最新文章