1. 内容简介
1.1 摘要
聚合以太网(RoCE)上的 RDMA 协议因其与传统以太网结构的兼容性而对数据中心网络产生了巨大的吸引力。然而,RDMA 协议只有在(几乎)无损网络上才有效,这就强调了拥塞控制在 RoCE 网络中的重要作用。遗憾的是,基于优先级流量控制(PFC)的本地 RoCE 拥塞控制方案存在许多缺点,如不公平、头线阻塞和死锁。因此,近年来人们提出了许多为 RoCE 网络提供额外拥塞控制的方案,以尽量减少 PFC 的缺点。不过,这些方案都是针对一般数据中心环境提出的。与使用商品硬件构建并运行通用工作负载的普通数据中心不同,高性能分布式培训平台部署了高端加速器和网络组件,并使用集体(All-Reduce、All-To-All)通信库专门运行培训工作负载。此外,这些平台通常有一个专用网络,将其通信流量与数据中心的其他流量分开。可扩展的拓扑感知集体算法本质上就是为了避免同播模式并优化流量平衡而设计的。由于这些显著特点,我们有必要重新审视以前提出的通用数据中心环境拥塞控制方案。在本文中,我们深入分析了在分布式培训平台上运行时,一些最先进的 RoCE 拥塞控制方案(DCQCN、DCTCP、TIMELY 和 HPCC)与 PFC 的对比。我们的研究结果表明,以前提出的 RoCE 拥塞控制方案对培训工作负载的端到端性能影响甚微,因此有必要根据分布式培训平台和工作负载的特点设计一种优化的、低开销的拥塞控制方案。
1.2 研究动机
标准的RoCE协议使用FPC协议控制阻塞,但是会带来不平衡、队头阻塞和死锁的问题
传统的基于RoCE的阻塞控制算法是基于通用的数据中心构建的
之前的阻塞控制协议(DCQCN、TIMELY、HPCC等)并不适用于DNN训练的场景
1.3 主要贡献
第一个在DNN分布式训练任务上进行阻塞控制方案评估的工作
使用ASTRA-sim和NS3使用不同的阻塞控制方案进行仿真验证
对每个现成的阻塞控制方案进行详细的分析,包括集合通信和DNN训练负载等
不同的最先进 RoCE 拥塞控制方案对端到端培训性能影响甚微
我们为设计一种针对分布式训练的优化且低开销的拥塞控制方案指明了方向
2. 实现方法
使用ASTRA-sim仿真
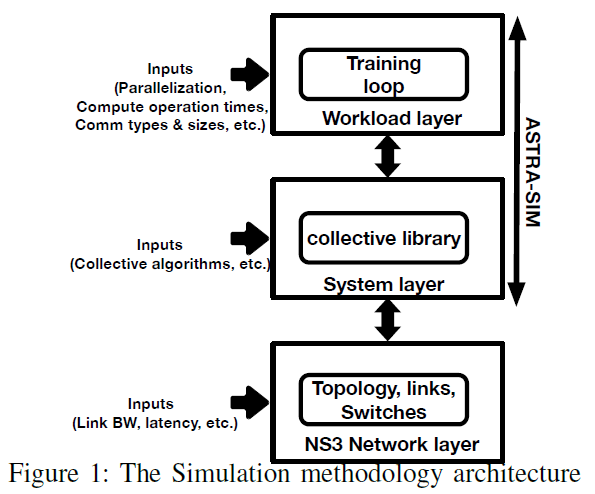
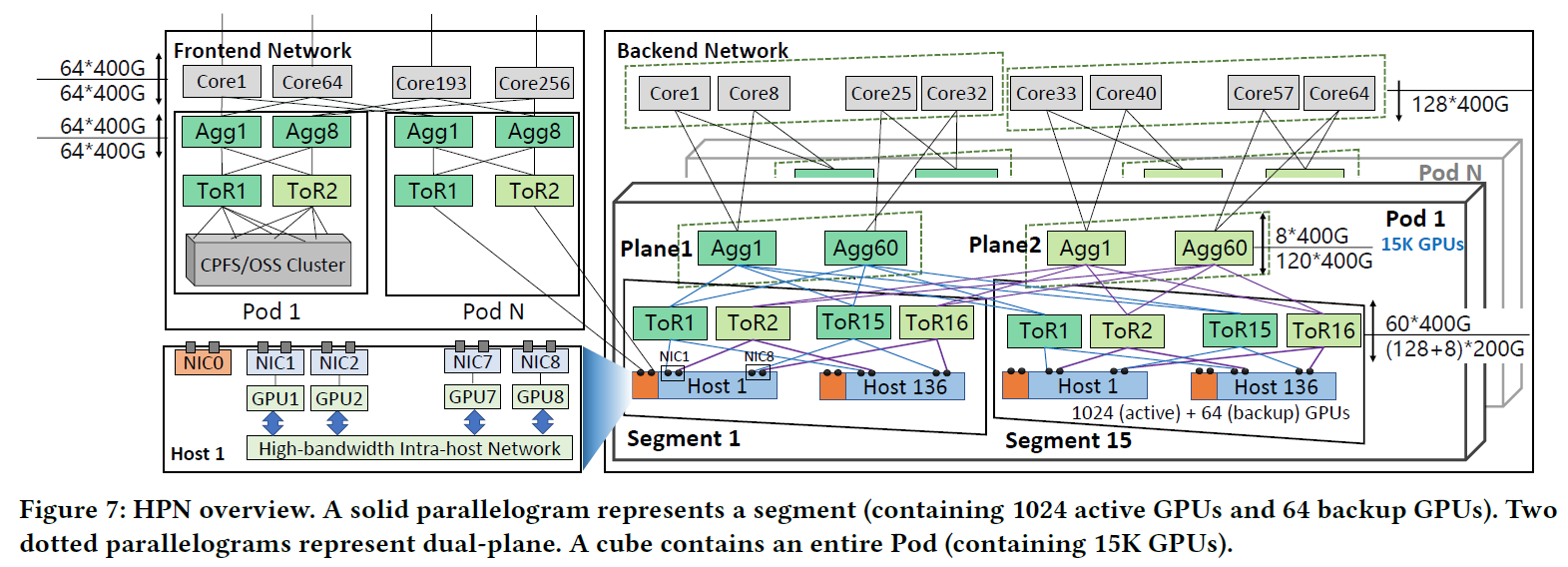
网络拓扑
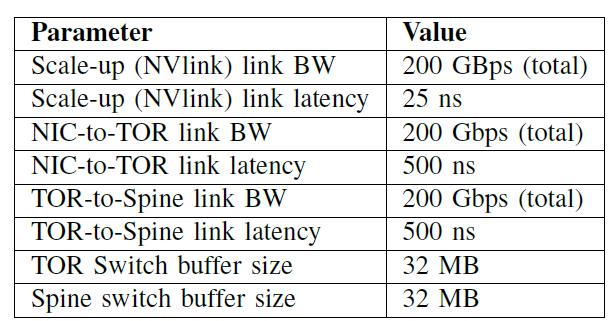
系统参数
3. 实验结果
3.1 Single-switch Incast micro-benchmark
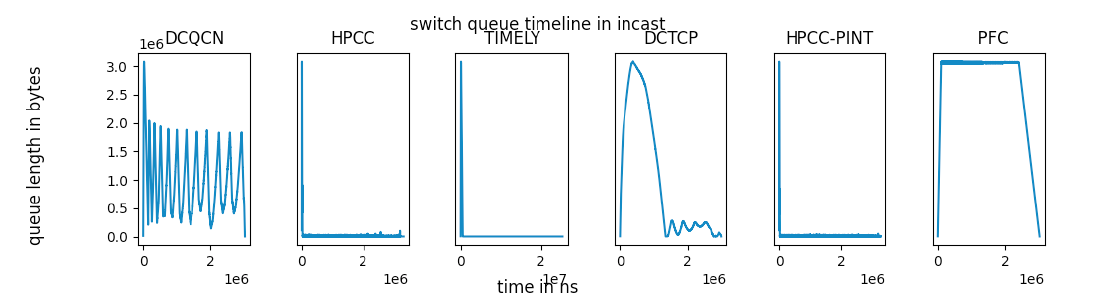
FPC only 队列快速满载,随后网络被反复暂停并重复这一过程
DCQCN在设置参数时确保没有FPC触发,且带宽率用率较高
DCTCP、TIMELY等在没有触发FPC帧的条件下
3.2 Single-switch Collectives Micro-benchmark
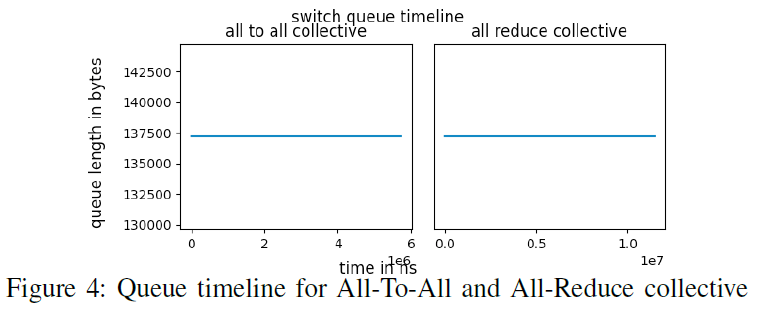
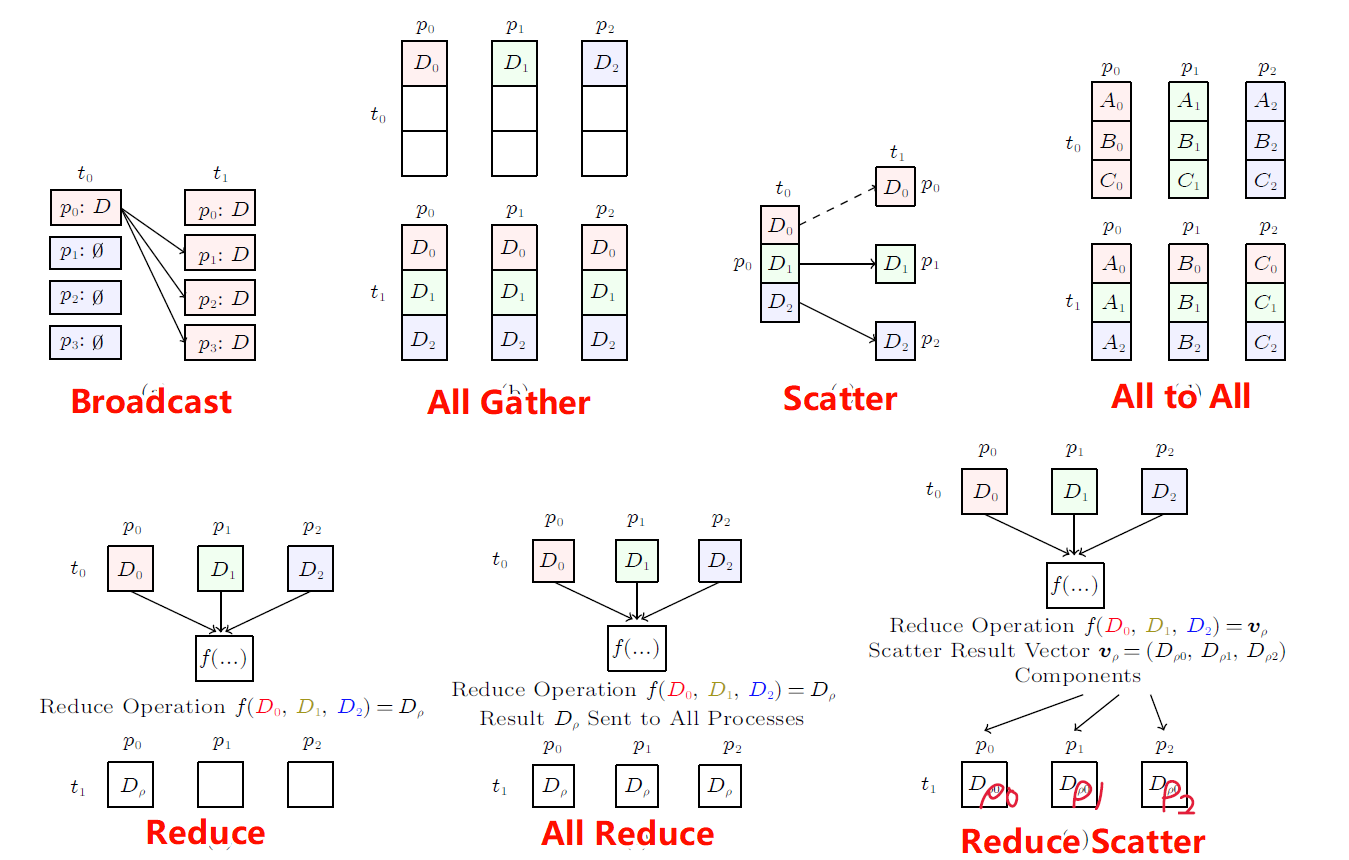
在8-128个GPU条件下进行All-To-All和All-Reduce集合通信
在集合通信条件下不存在阻塞,所以没有阻塞控制算法对其无效
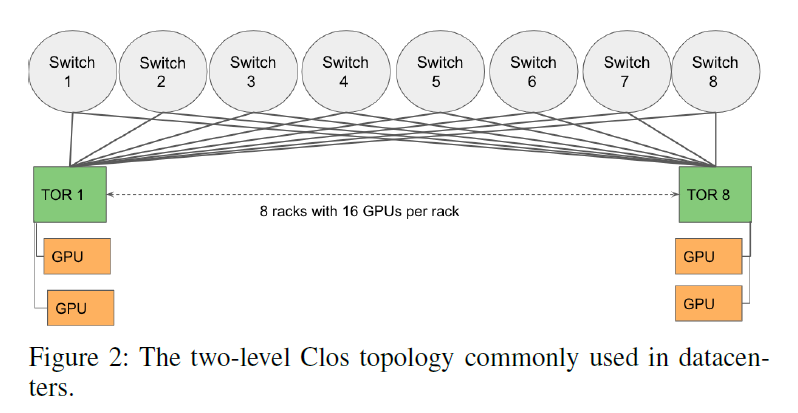
3.3 Two-level CLOS topology
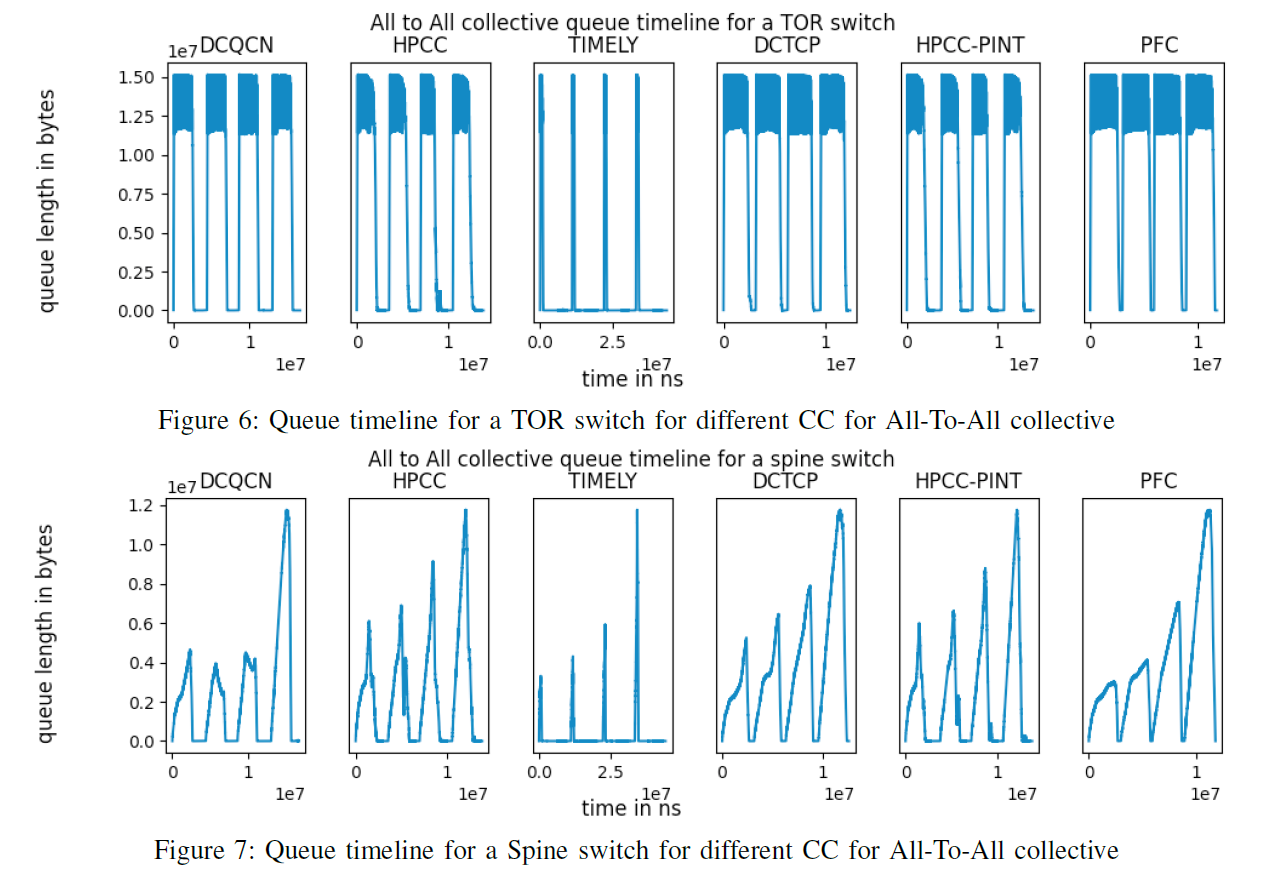
在TOR网络下的All-To-All集合通信算法对交换机缓存的影响
除了TIMELY阻塞控制算法外,其他算法在集合通信的条件下都有相似的表现
怀疑是TIMELY的参数设置不佳导致TIMELY算法的带宽利用率较低
3.4 Real Workload: DLRM Results
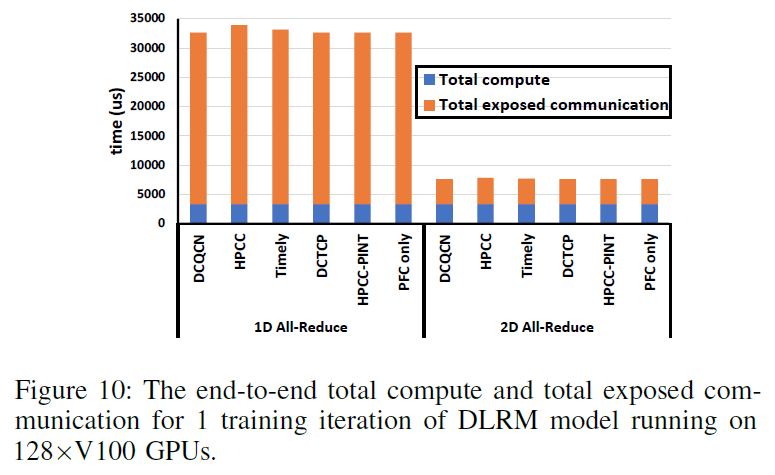
不同的阻塞控制算法对其影响的程度小于4%
TIMELY的效果并没有像仿真的时候效果那么差
在真实的单任务训练过程中或者在NS3仿真时由于集合通信算法的加持下:
是否几乎没有出现网络阻塞的情况,进而不同的阻塞控制算法几乎没有太大的影响?
是否已经达到了理想的带宽利用率,所以阻塞控制算法收益不大?