1. 内容简介
1.1 摘要
为了应对机器学习(ML)模型的创新,生产工作负载发生了翻天覆地的变化。TPU v4 是谷歌第五个特定领域架构(DSA),也是第三台用于此类 ML 模型的超级计算机。光路交换机(OCS)可以动态地重新配置其互连拓扑结构,以提高规模、可用性、利用率、模块化、部署、安全性、功耗和性能;如果需要,用户可以选择扭曲的三维环形拓扑结构。与 Infiniband 相比,OCS 的成本更低、功耗更小、速度更快,OCS 和底层光学元件占系统成本的比例小于 5%,占系统功耗的比例小于 3%。每个 TPU v4 都包含 SparseCores 数据流处理器,可将依赖嵌入的模型加速 5-7 倍,但仅占用 5% 的芯片面积和功耗。自 2020 年部署以来,TPU v4 的性能是 TPU v3 的 2.1 倍,性能/瓦特数提高了 2.7 倍。TPU v4 超级计算机的芯片数量为 4096 个,是 TPU v3 的 4 倍,因此整体速度提高了近 10 倍,再加上 OCS 的灵活性和可用性,大型语言模型的平均训练速度可达到峰值 FLOPS/second 的 60%。对于类似大小的系统,它比 Graphcore IPU Bow 快 4.3-4.5 倍,比 Nvidia A100 快 1.2-1.7 倍,功耗低 1.3-1.9 倍。谷歌云能源优化仓库规模计算机内的 TPU v4 与典型内部数据中心的当代 DSA 相比,能耗降低约 2-6 倍,二氧化碳排放量降低约 20 倍。
1.2 主要工作(与网络相关的)
TPU v4采用了3D Torus网络结构,将TPU芯片按照三维立方体排列,提供高带宽、低延迟的通信链路
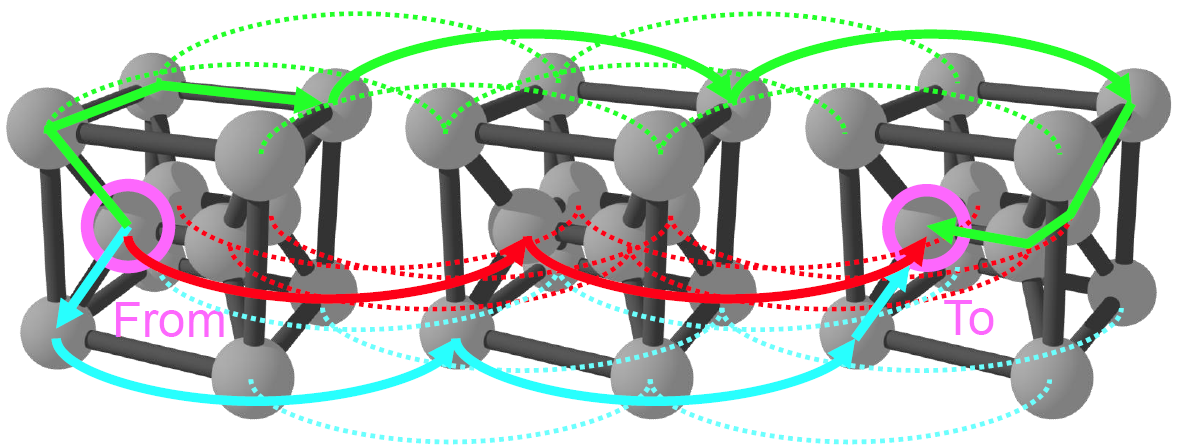
为进一步优化通信性能,TPU v4引入了Twisted Torus结构。通过重新布线,Twisted Torus减少了最坏情况下的通信延迟,增加了网络的双向带宽
通过采用Twisted Torus结构,TPU v4显著优化了全网通信性能,减少了通信延迟,提高了吞吐量
2. 主要方法
2.1 Twisted Torus & 3D Torus
TPUv4使用OCS可以动态的调整网络结构,例如将ML的任务切分成512个子任务,可以使用Cigar形状的4x4x32,也可以使用Cube的8x8x8,不同的拓扑有不同的性能
针对完美Cube的Torus网络的训练性能较好(例如使用512个TPU组成8x8x8的拓扑),但是对于非完美的Cube的拓扑结构可能较差
Twisted Torus建立了 4^3 个立方体之间的一些链接,以减少最坏情况下的延迟
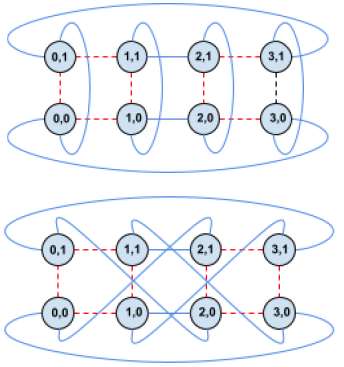
每个 TPU 都标有其在切片中的坐标
电气连接(红色虚线)保持固定,通过利用 OCS 的灵活性,光连接(蓝色实线)可以从矩形环重新配置为扭曲环,而无需对机器进行任何物理重新布线
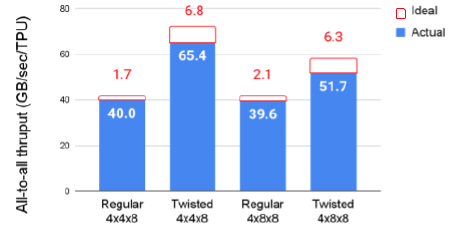
测量为稳定状态(总传输大小较大),单个 DMA 为 4 KiB
每列显示了与理想峰值的理论偏差,以叠加条形图的形式出现,并在测量结果上方标注
2.2 Distribution of Topologies
生产中使用的切片拓扑结构示例:
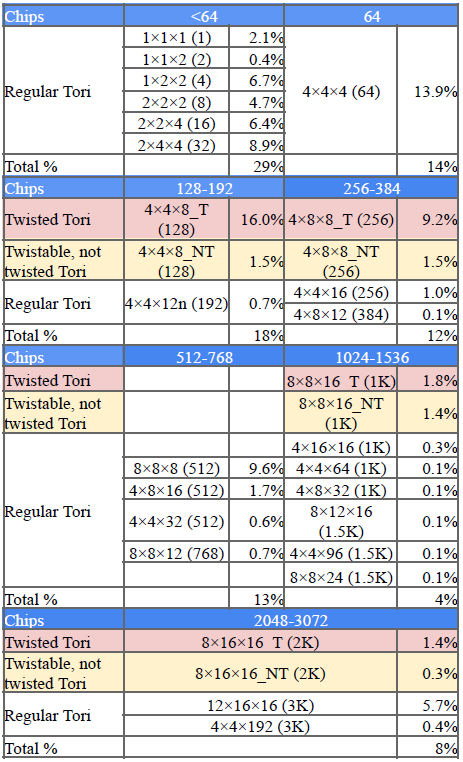
远小于4^3的Task可以使用2D Mesh,占比29%
剩下的71%中,只有使用nxnx2n或者nx2nx2n的可以使用Twisted Torus,占比33%(48% of 71%)
实际使用Twisted的只有28%(86% of 33%)
换句话说,在多于4^3个Tasks中,有超过40%的可以使用Twisted Torus