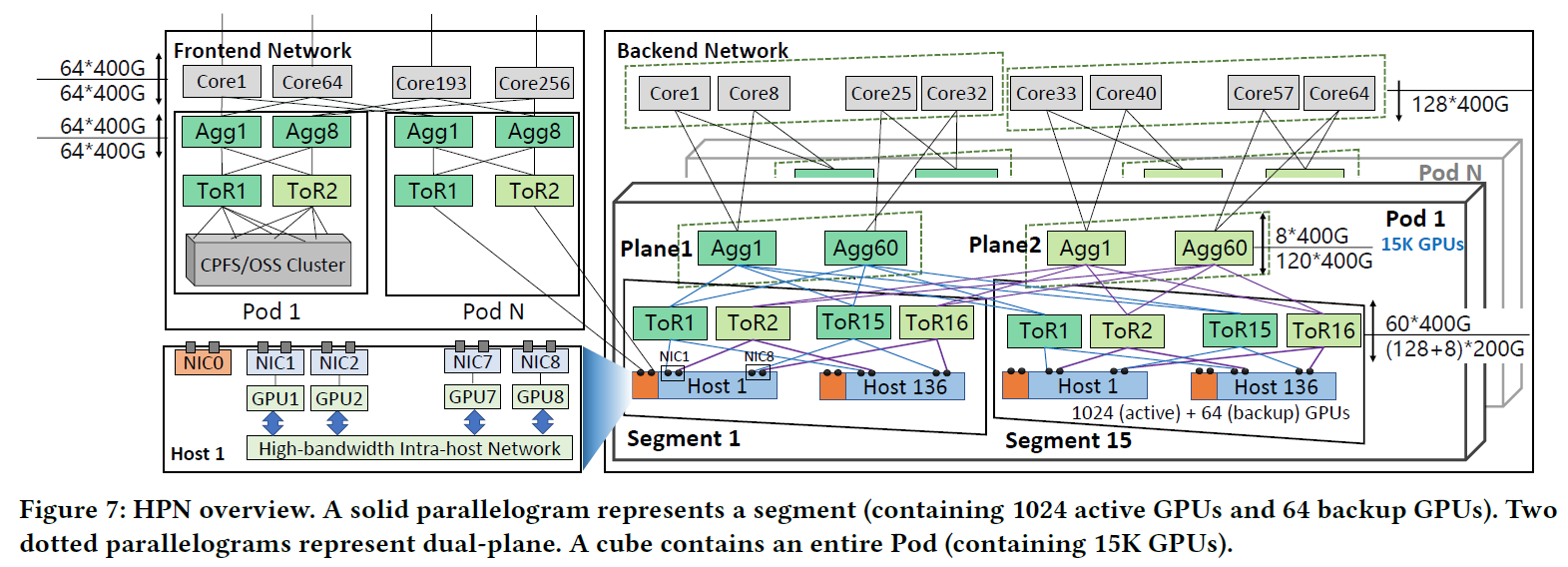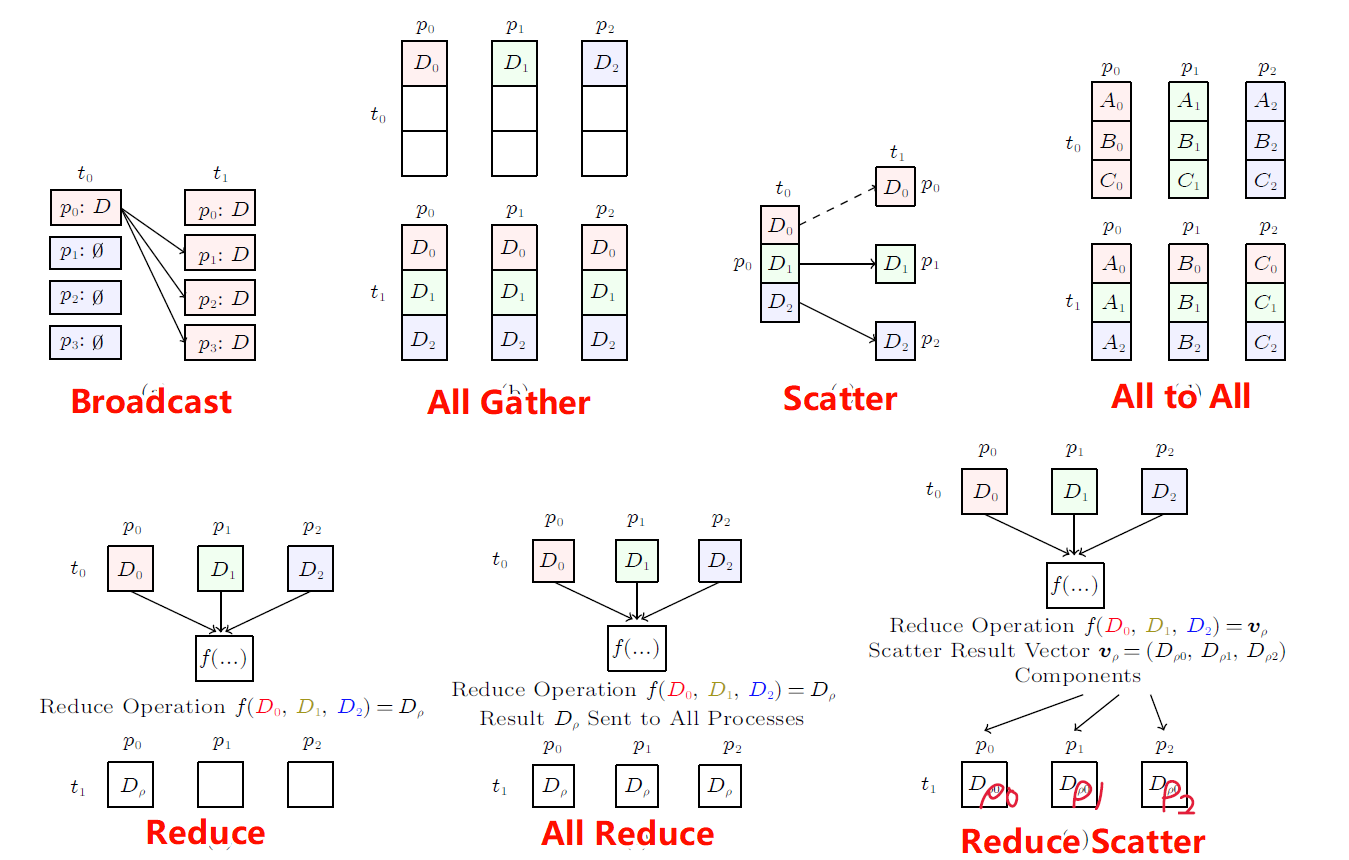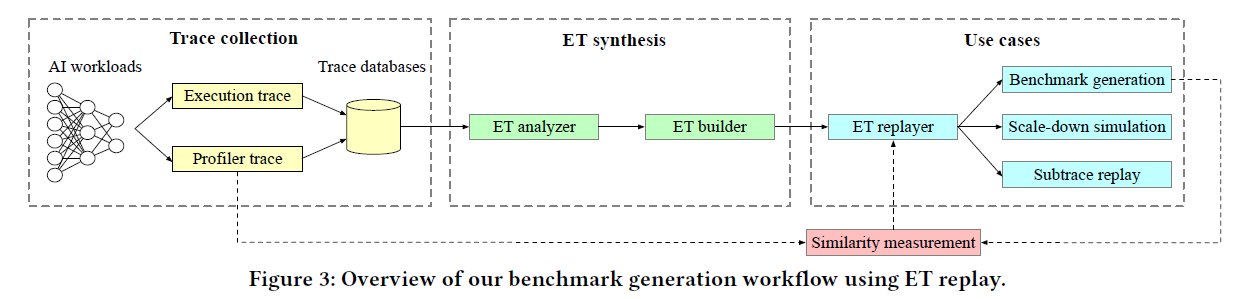
1. 内容简介
1.1 摘要
拥塞控制(CC)是高速网络实现超低延迟、高带宽和网络稳定性的关键。根据多年运营大规模高速 RDMA 网络的经验,我们发现现有的高速拥塞控制方案在实现这些目标方面存在固有的局限性。在本文中,我们提出了 HPCC(高精度拥塞控制),一种能同时实现上述三个目标的新型高速拥塞控制机制。HPCC 利用网内遥测(INT)获取精确的链路负载信息,并精确控制流量。通过解决拥塞期间 INT 信息延迟和对 INT 信息反应过度等难题,HPCC 可以在避免拥塞的同时快速收敛以利用空闲带宽,并能保持近乎零的网内队列以实现超低延迟。HPCC 在硬件上的部署也是公平、简单的。我们利用商品可编程网卡和交换机实现了 HPCC。在我们的评估中,与 DCQCN 和 TIMELY 相比,HPCC 可将流量完成时间缩短达 95%,即使在大规模数据交换的情况下也几乎不会造成拥塞。
1.2 研究动机
FPC风暴:网络上一旦出现阻塞,根据RoCEv2协议会发送FPC暂停帧,进而导致网络停摆
超大延迟:由于阻塞网络队列的影响,神经网络训练时的延迟大到超乎想象
收敛速度慢:由于依赖的Feedback信息颗粒度不够,导致处理大规模阻塞事件时收敛慢
不可避免的缓存队列:由于DCQCN和TIMELY等都依赖队列信息的感知,因此无法避免延迟大的问题
复杂的调参:不同的应用有不同的流量模式,不同的环境有不同的拓扑、链接速度、交换机缓冲区大小等,因此在不同环境下部署不同应用时都要对参数进行微调
1.3 主要贡献
HPCC的发送端可以快速提高发送速率以提高带宽利用率,同时可以快速降低发送速率,以避免产生阻塞
HPCC的发送端可以快速的调整发送速率以确保每条连接的输入速率略小于其带宽能力
一旦发送速率在路由中精确计算出结果,HPCC只需要3个独立的参数就可以调整其效率和公平性
2. 实现方法
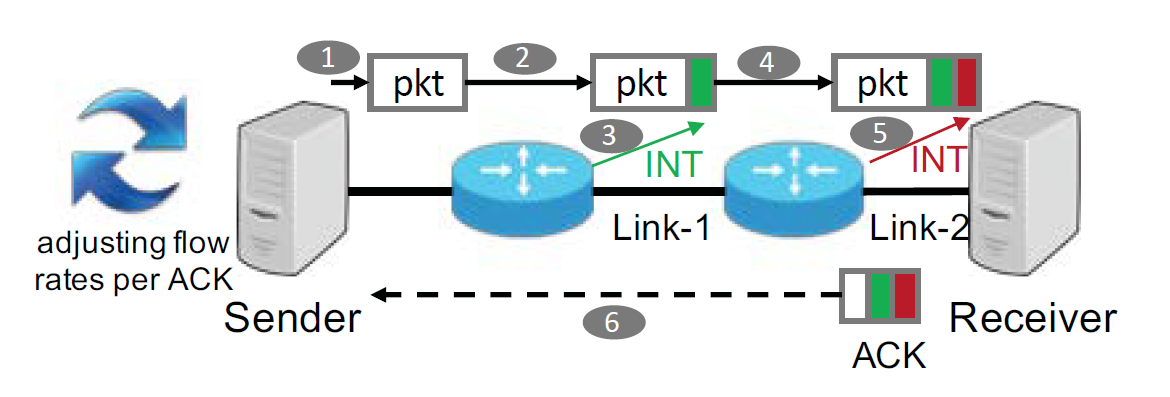
Sender发送输入给Receiver,数据在经过中间的Switch时会被Switch添加一些INT数据作为metadata,Receiver在ACK时把这些metadata传递给Sender,然后Sender根据这些INT数据调整自己的发送速率
Sender通过发送窗口限制在途数据的数量
基于在途数据量的阻塞控制信号和控制策略
快速响应而不是过响应
实现方法,FPGA网卡
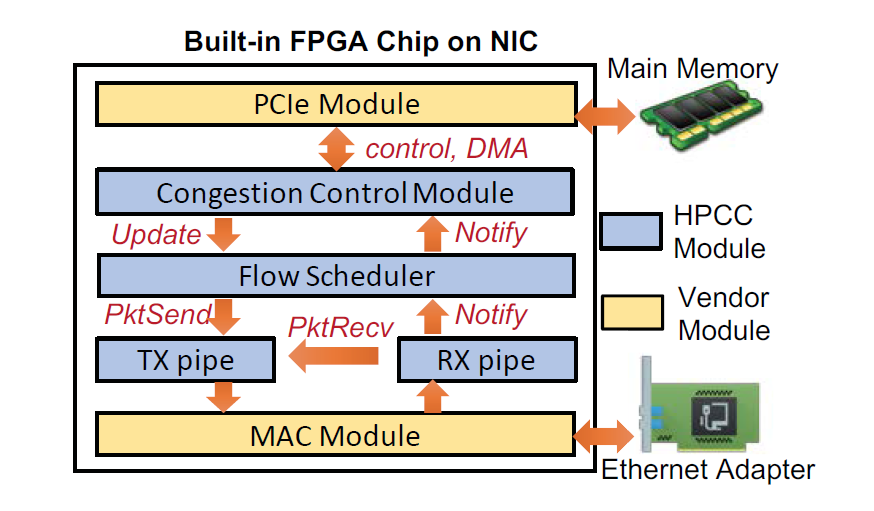
3. 实验结果
小规模测试+大规模NS3仿真
测试条件 - 网络拓扑
The testbed topology mimics a small scale RDMA PoD in our production. The testbed includes one Agg switch and four ToRs (ToR1-ToR4) connected via four 100Gbps links. There are 32 servers in total and each server has two 25Gbps NICs. 16 servers are connected to ToR1 and ToR2 via two uplinks, and the other 16 servers are connected to ToR3 and ToR4. The base RTT is 5.4μs within a rack and 8.5μs cross racks.
The topology in the NS3 simulations is a FatTree. There are 16 Core switches, 20 Agg switches, 20 ToRs and 320 servers (16 in each rack), and each server has a single 100Gbps NIC connected to a single ToR. The capacity of each link between Core and Agg switches, Agg switches and ToRs are all 400Gbps. All links have a 1μs propagation delay, which gives a 12μs maximum base RTT. The switch buffer size is 32MB which is derived from real device configurations. The whole network is a single RDMA domain.
测试条件 - 流量负载
We use widely accepted and public available data center traffic traces, WebSearch and FB_Hadoop in both testbed experiments and simulations.
We adjust the flow generation rates to set the average link loads to 30% and 50% respectively. We also create some simple artificial traffic loads to evaluate the microbenchmarks of HPCC.
测试条件 - 对比方法
DCQCN
TIMELY
实验结果
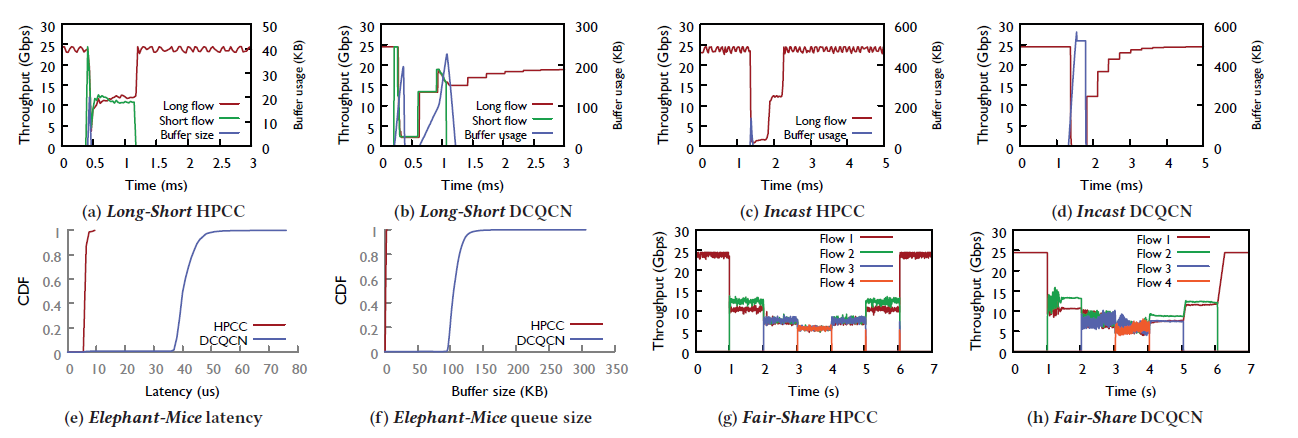
(a) vs. (b) 在Long Flow条件下,HPCC的吞吐量优于DCQCN,Buffer Size远小于DCQCN
(c) vs. (d) 在Incast流量下,HPCC的吞吐量与DCQCN相似
(e) HPCC的延迟远小于(10倍)DCQCN
(f) HPCC的Buffer Size远小于DCQCN
(g) vs. (h) HPCC的Fairness略好于DCQCN,带宽抖动小于DCQCN