I. 前置内容
在了解集合通信(Collective Communication)之前要先了解点P2P对点通信(Point-to-Point)。P2P通信通常为两个不同进程间的通信,是1对1的; 在MPI规范中,既有同步阻塞的P2P接口:MPI_send和MPI_Recv接口,也定义了非阻塞的P2P接口如:MPI_Isend、MPI_Irecve。
集合通信和P2P通信是相对应的,集合通信则是1对多或是多对多的。在分布式系统中,各个节点间往往存在大量的集合通信需求,而我们可以用消息传递接口(Message Passing Interface,MPI)来定义一些比较底层的消息通信行为譬如Reduce、Allreduce、Scatter、Gather、Allgather等。
1.1 系统架构
集合通信算法的优化往往与其对应的网络拓扑和系统架构有直接关系,通常情况下,一个节点内的GPU-GPU或GPU-CPU之间的结构成为系统架构,节点之间的网络连接称为网络拓扑,一种确定的系统架构会有确定的网络拓扑架构。
在HPC领域有很多经典的系统架构和网络拓扑,例如:Summit system或者Lassen system等。本文主要由于发表于2021年,很多系统架构和指标数据与当先最新数据差异较大,但是为了方便后续的理解,本文后续还是以Summit system和Lassen system为例进行分析。
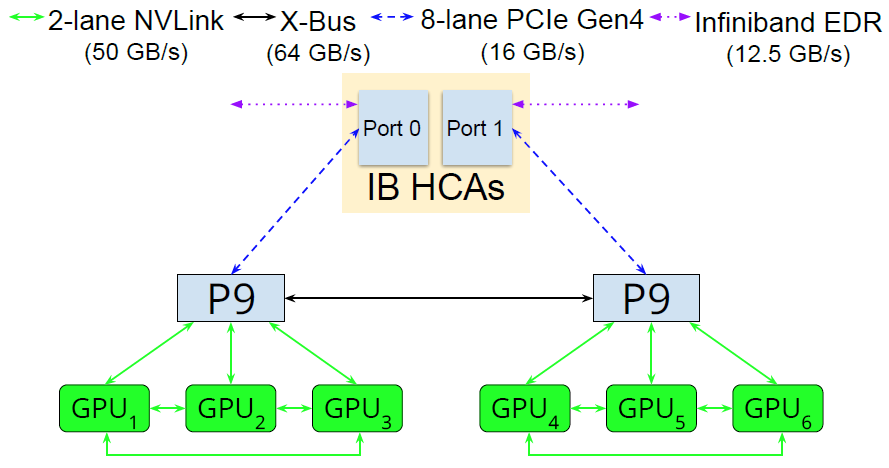
简化的Summit System和Lassen System(论文中的结构)
每个节点包含6个GPU和2个CPU,每3个GPU和1个CPU组成一个Group,使用NVLink进行连接,CPU与CPU之间使用X-Bus进行连接,同时与IB网卡使用PCIe进行连接,节点间使用IB协议进行组网。NVLink、NVSwitch、IB等硬件设备的概念将会在下一节中介绍。
1.2 相关组件
NVLink and NVSwitch
NVLink和NVSwitch是一种可支持服务器内和服务器间实现高级多 GPU 通信的基础模组。第四代NVLink技术可为多 GPU 系统配置提供高于以往 1.5 倍的带宽,以及增强的可扩展性。第三代NVSwitch基于NVLink的高级通信能力构建,可为计算密集型工作负载提供更高带宽和更低延迟。Mellanox InfiniBand
InfiniBand(直译为“无限带宽”技术,缩写为IB)是一个用于高性能计算的计算机网络通信标准,它具有极高的吞吐量和极低的延迟,用于计算机与计算机之间的数据互连。InfiniBand也用作服务器与存储系统之间的直接或交换互连,以及存储系统之间的互连。常用的IB交换机/网卡带宽普遍为为400GB/s。Remote Direct Memory Access (RDMA)
RDMA是一种概念,在两个或者多个计算机进行通讯的时候使用DMA, 从一个主机的内存直接访问另一个主机的内存。
1.3 (Non-)Personalized All-to-All
1.3.1 Non-Personalized All-to-All
Non-Personalized All-to-All(通常称为 MPI_Allgather)是一种 MPI 集体通信模式,是 MPI_Gather 和 MPI_Bcast 的结合。所有进程按等级顺序从其他进程收集数据。操作结束时,每个进程都将与所有其他进程交换数据。
1.3.2 Personalized All-to-All
Personalized All-to-All称为 MPI_Alltoall,与 MPI_Allgather 类似,所有进程都相互共享数据。然而,每个进程都会向其他进程发送不同的数据,从而形成一种个性化的集体通信模式(即,每个进程都会向每个其他进程发送不同的数据块)
1.4 相关算法
1.4.1 Ring
每个进程i发送数据给(i+1) \% N并从(i-1) \% N接收数据,但是这种方法会带来过高的延迟。
1.5.2 Recursive Doubling
每个进程i在第k (0<=2k<N)步发送数据给(i \ XOR \ 2^k)并从(i \ XOR \ 2^k)接收数据。这种方法能够有效降低延迟,但是缺点也显而易见,就是当进程数N不是2的幂的时候很不友好,需要特殊处理。
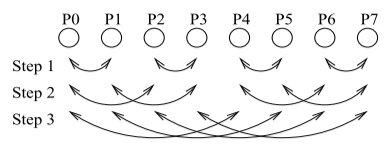
Recursive Doubling算法
1.5.3 Bruck
Bruck算法可以看做是RD算法的一个改进,每个进程i第k (0 ≤ k < \log_2 N)步发送数据给(i-2k) \% N并从(i-2k) \% N接收数据。
Bruck算法是优化后的环形算法,进一步降低通信的次数。它利用了倍增的思想:每次接收到数据后,本地数据量翻倍,然后把所有本地数据发送给没有这些数据的下一个节点。
具体来说,对于节点i,在第j次通信的时候(j从1开始),把自身的所有数据发送给i−2j−1个节点。这样的话,仅需要发送\log m次。算法流程如下图所示:
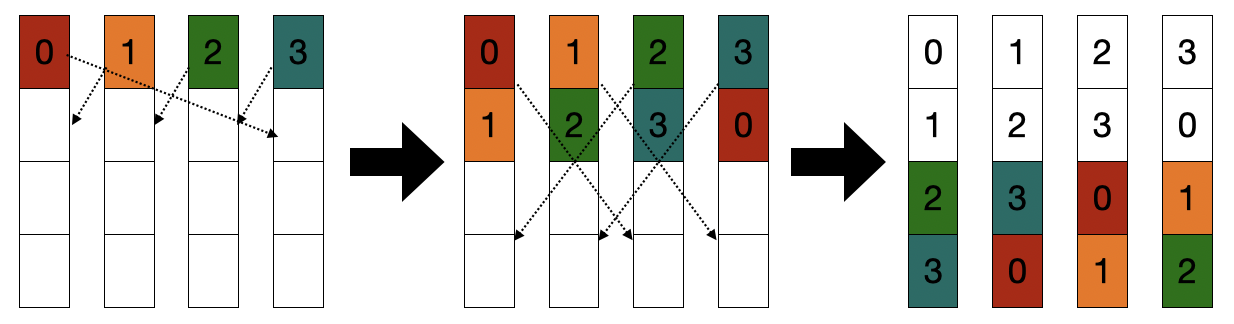
Bruck算法
1.5.4 Pairwise-Exchange
每个进程i在第k (0<=2k<N)步发送数据给(i \ XOR \ {2^k}) \% N并从(i \ XOR \ {2^k}) \% N接收数据,其中XOR表示逻辑异或的位运算。同样这种算法对于进程数N不是2的幂的时候很麻烦。
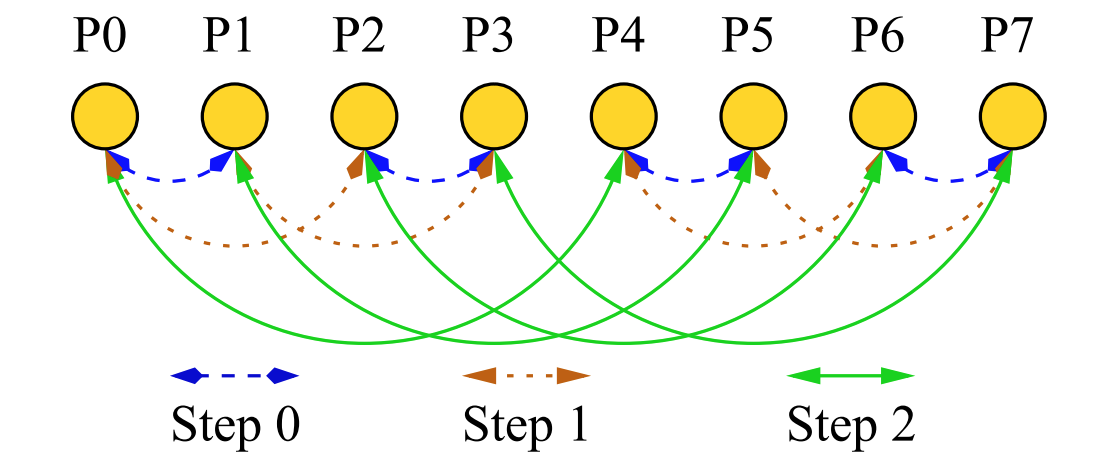
Pairwise-Exchange算法
1.5.5 Scatter-Destination
TODO
A. K. Singh, S. Potluri, H. Wang, K. Kandalla, S. Sur, and D. K. Panda, “Mpi alltoall personalized exchange on gpgpu clusters: Design alternatives and benefit,” in 2011 IEEE International Conference on Cluster Computing, Sep. 2011, pp. 420–427.
1.5.6 Direct
直接根据目的直接send和recv不进行任何调度的方法,这里就是指 p 个进程,每个进程都调用 p-1 个MPI_Irecv和MPI_Isend,然后MPI_Waitall完事。
1.5.7 Inplace
TODO
1.6 评价标准
OSU 微基准测试(OSU micro-benchmarks)具有一系列 MPI 基准测试,可衡量各种 MPI 操作的性能:
点对点 MPI 基准:延迟、多线程延迟、多对延迟、多带宽/消息速率测试带宽、双向带宽
集体 MPI 基准:各种 MPI 集体操作的集体延迟测试,例如 MPI_Allgather、MPI_Alltoall、MPI_Allreduce、MPI_Barrier、MPI_Bcast、MPI_Gather、MPI_Reduce、MPI_Reduce_Scatter、MPI_Scatter 和向量集体。
单侧 MPI 基准:一侧放置延迟(主动/被动)、一侧放置带宽(主动/被动)、一侧放置双向带宽、一侧获取延迟(主动/被动)、 MVAPICH2(MPI-2 和 MPI-3)的单侧获取带宽(主动/被动)、单侧累积延迟(主动/被动)、比较和交换延迟(被动)以及获取和操作(被动)。
II. 论文简介
2.1 摘要
近年来,GPU 增强型集群在高性能计算 (HPC) 领域变得越来越普遍,从而引发了对更高效的多 GPU 通信的需求。这使得探索通过 MPI 等通信中间件实现的性能增强变得越来越重要,以便充分利用这些系统上可用的 GPU。在本文中,我们提出了大规模密集 GPU 系统上分层 All-to-all 集体通信的局部感知和自适应方案。所提出的算法利用 GPU 之间的 NVLink 互连提供的高带宽来重叠通信延迟。我们专注于个性化和非个性化的全民集体沟通。这些是现代科学计算应用程序的组件,利用矩阵转置和三维快速傅立叶变换 (FFT),并且与具有模型和混合并行性的深度学习工作负载变得更加相关。对执行三维 FFT 的应用程序内核进行的性能评估表明,所提出的个性化 all-to-all 方案可以将 Lassen 系统上 256 个 GPU 上的执行时间缩短 15-25%。我们展示了在多达 128 个 GPU 上进行深度学习训练时使用的分布式 K-FAC 的训练时间缩短了大约 8%。我们还证明,与 Summit 和 Lassen 系统上最先进的 MPI 库相比,非个性化和个性化全基准测试的性能分别提高了约 22% 和 30%1。
2.2 主要贡献
在密集 GPU 系统上设计了一种分层、自适应和高利用率的个性化和非个性化全能通信算法。
提出一种新的 All-to-all 算法,分解成对通信模式,并利用 GPU 之间可用的互连(例如 NVLink)来最大限度地减少链路空闲时间。
提出一种先进的分层算法,实现节点间和节点内通信之间的高度重叠,以提高 All-to-all 和 Allgather 通信的性能。
对最先进的 MPI 库中现有的 All-to-all 和 Allgather 通信算法进行综合评估。
使用OSU微基准、3D FFT 应用内核和 KFAC 分布式 DNN,对所提出的设计和各种 CUDA 感知通信库(MVAPICH2GDR、Spectrum-MPI、NCCL 和 OpenMPI)进行 All-to-all 和 Allgather 集体的性能评估优化。
2.3 题目关键词
自适应:根据Message Size的不同选择最合适的算法
分层:在节点内选择一个GPU作为Leader,只有Leader能在节点间传输数据
大消息:在Large Message上优化效果较好
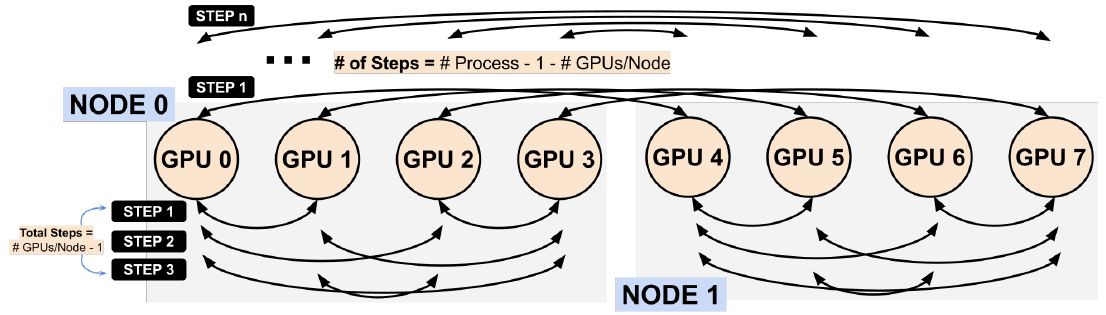
III. 实现步骤
All to All 与 All Gather 相比较,区别在于:All Gather 操作中,不同进程向某一进程收集到的数据是完全相同的,而在 All to All 中,不同的进程向某一进程收集到的数据是不同的。在每个进程的发送缓冲区中,为每个进程都单独准备了一块数据4。
3.1 Non-Personalized All-to-All
3.1.1 实现思路
主要目的是利用节点内高速连接的网络提高密集GPU集群种All Gather集合通信算法的效率,通过与节点间通信的Overlap,隐藏节点间通信的时间,进而提高NVLink的利用率。
本文所提出的算法针对基于树状的网络拓扑结构,基于RD方法改进而来的。利用两个通信器分别连接节点内与节点间的两层网络,在节点内与节点间同步传输数据实现节点内与节点间的Overlap通信。
3.1.2 实现步骤
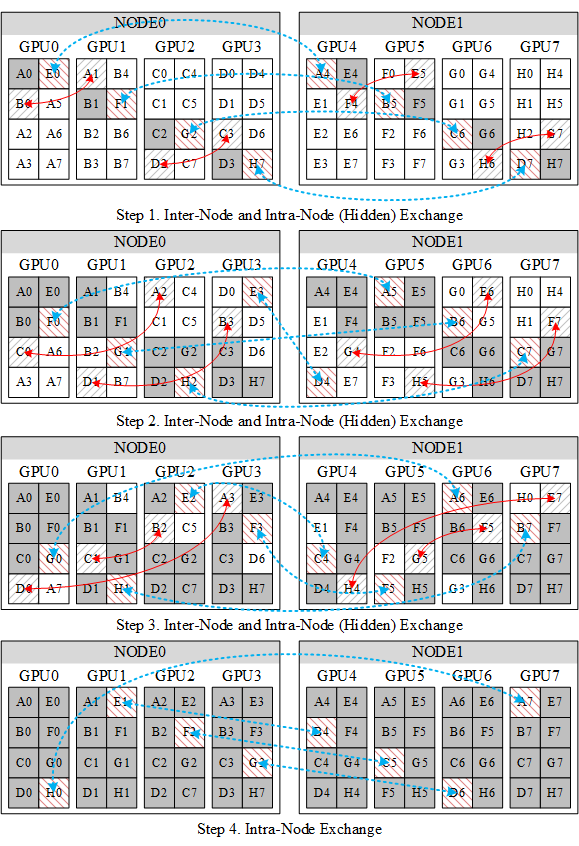
A. 2 Nodes
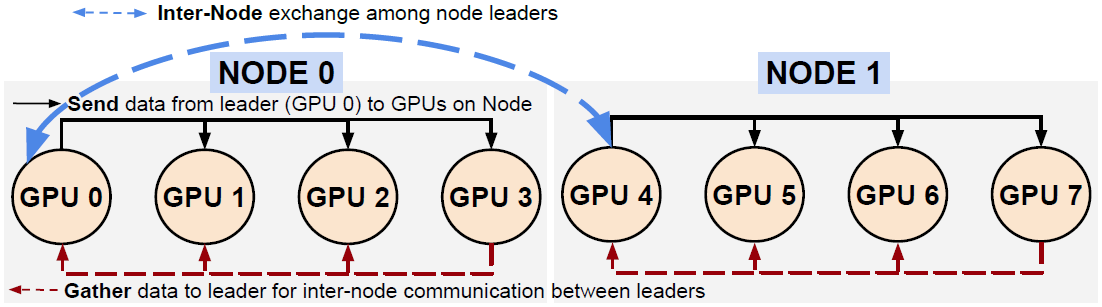
Allgather on 2 Nodes (8 Processes)
原论文配图勘误:
根据文章内容描述,图中的蓝色虚线应该由
Inter-Node改为Intra-Node节点内的Gather操作方向应该为
GPU1-->GPU0,GPU2-->GPU0
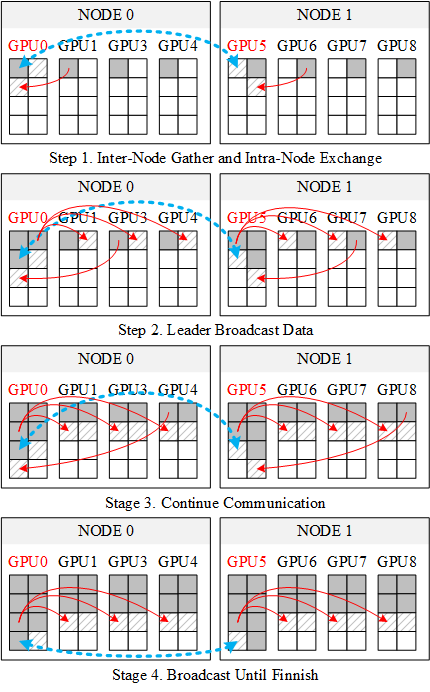
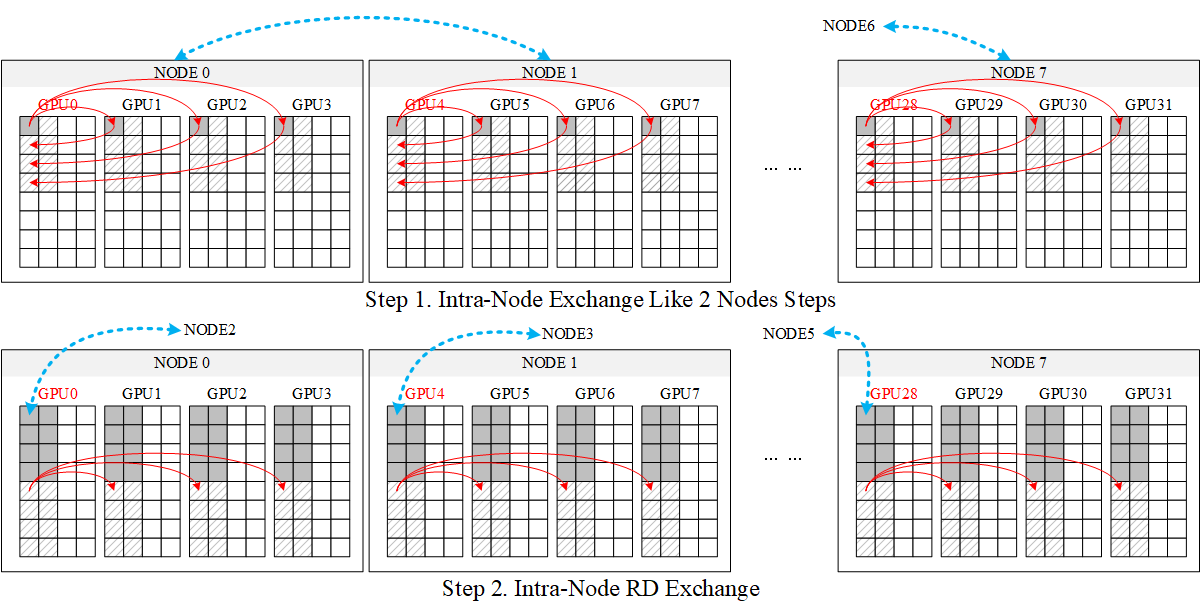
B. 8 Nodes
Allgather on 8 Nodes (32 Processes)
8节点与单节点操作过程类似,类似2节点的过程,具体过程如下
3.1.3 小结
由于Non-Personalized All-to-All的任一进程向其他进程发送的数据量和接收的数据量是相同的,因此在无收敛的网络结构种可以利用节点内通信的时间与节点间的通信时间同步进行,以提高效率。但是当节点内通信与节点间通信的数据量不同时,可能导致该时间无法完美Cover,导致集合通信的效率下降。
在Summit system或者Lassen system中由于节点内跨CPU通信带宽受X-Bus带宽的限制,因此在实践时可能会造成阻塞导致集合通信效率降低。
3.2 Eager Personalized All-to-All
3.2.1 实现思路
本文提出的Eager Personalized All-to-All算法是基于优化后的Pairwise通信,主要目的是隐藏节点间通信的时间。
3.2.2 实现步骤
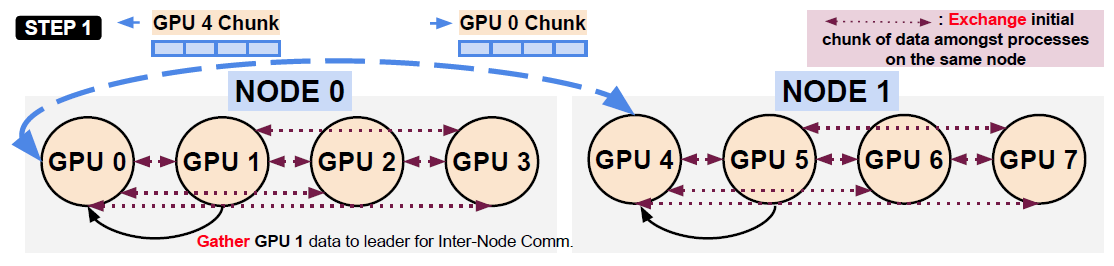
Eager All-to-all on 2 Nodes (8 Processes)
3.2.3 小结
这种方法的好处是可以隐藏前几步的潜在的Intra-Node通信耗时。
假定Inter-Node的连接方式为NVLink,Intra-Node的连接方式为IB,在Intra-Node通信时,GPU0 <--> GPU4传输数据的动作会与GPU1 <--> GPU5争抢IB交换机带宽,导致算法效率下降。
3.3 Hierarchical and Adaptive All-to-All
3.3.1 实现思路
传统的All-to-All算法大多按照Pairwise或Scatter实现,这种实现方式的性能严重受IB交换机的带宽限制。本文所提出的方法利用Leader进行Inter-Node和Intra-Node的分层解决该问题。同时对消息的大小具有一定的自适应性,算法会根据Message Size的不同自动选择最优的算法。
3.3.2 实现步骤
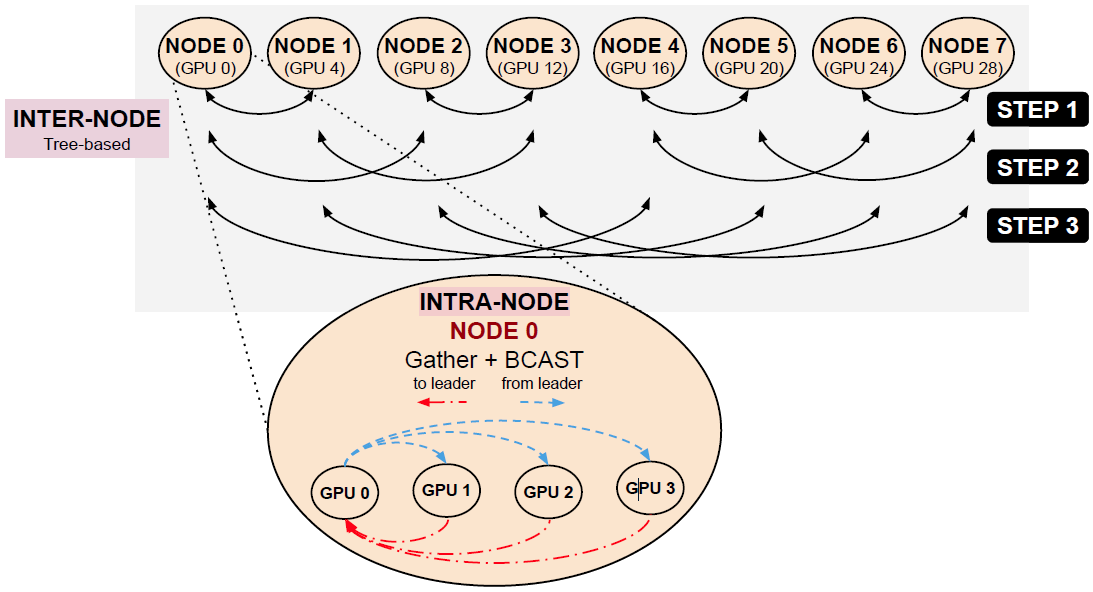
每个Node选择一个Leader,Leader之间进行Exchange数据,同时拿到数据后直接进行Gather和Scatter操作。以下的每一个步骤都是同时完成的,以确保在通信的时候没有IDLE时刻。
Hierarchical All-to-all: Step 1 of Execution
同节点内的GPU使用NVLink相互交换(P2P直接收发)初始化的数据块(紫色虚线)
NODE0.GPU1把对应的数据块Gather到NODE0.GPU0 (Leader)的临时Buffer(Sender Buffer)中NODE0.GPU0 (Leader)发送自己Send Buffer中的数据到NODE1.GPU4 (Leader)中
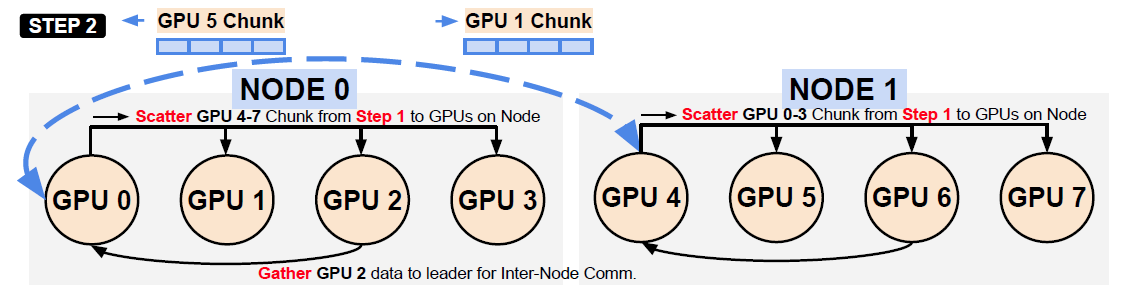
Hierarchical All-to-all: Step 2 of Execution
当
NODE0.GPU0 (Leader)和NODE1.GPU4 (Leader)收到对应的数据时直接Scatter到其他的GPU上同时
NODE0.GPU2的数据Gather到NODE0.GPU0 (Leader)上
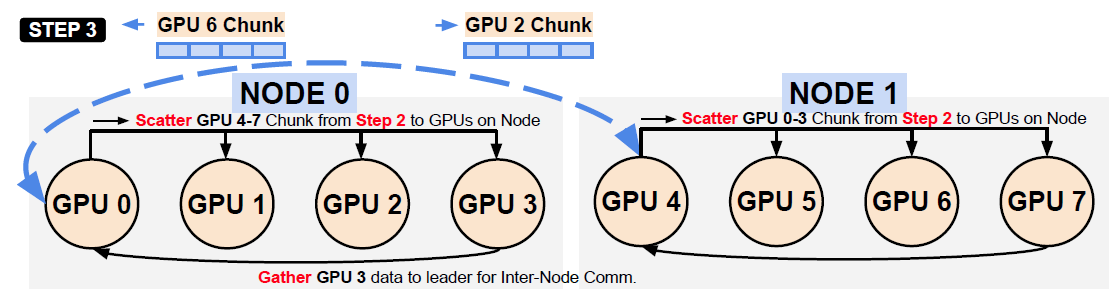
Hierarchical All-to-all: Step 3 of Execution
重复以上操作,直到一个节点内的全部数据完成
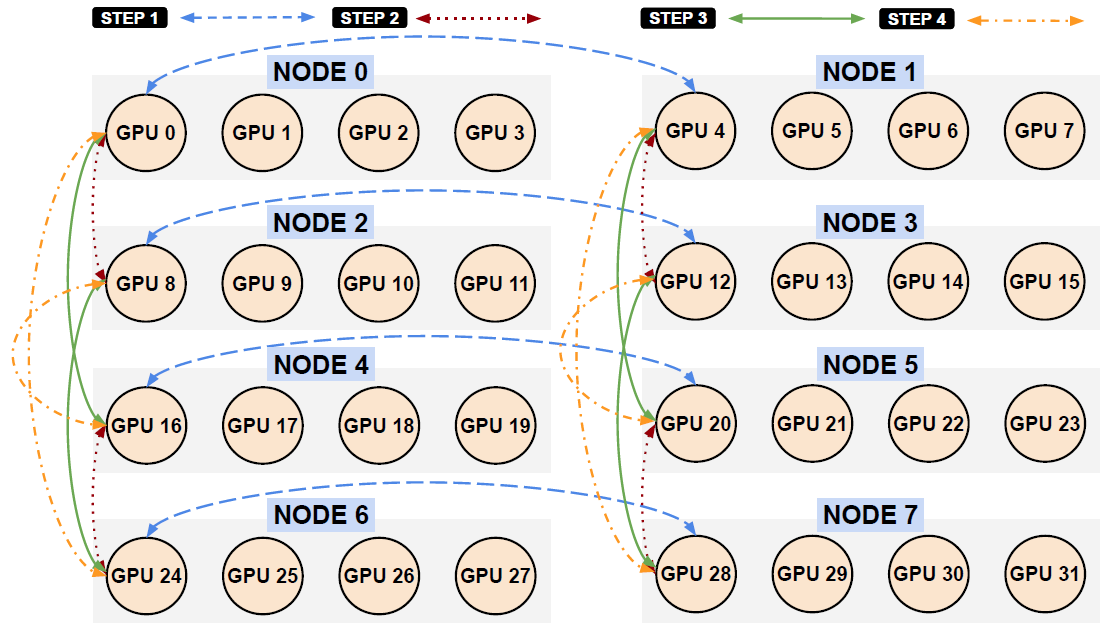
Hierarchical All-to-all: Inter-Node Communication Pattern Between Node Leaders
利用Pairwise算法在Leader之间交换数据,同时Leader会把数据Scatter到节点内的其他GPU上
3.3.3 小结
在节点内的传输过程类似Eager Personalized All-to-All算法,但是通过引入Leader的分层机制解决了同一个节点内的GPU抢占X-BUS带宽的问题。
IV. 实验结果
本文使用到的抓取性能数据的工具有mpiP、nvprof、INAM等,测试的指标主要是Benchmark、算法应用性能、其他的CUDA并行库。
4.1 Benchmark-Level Performance
测试条件:Lassen system,64个Node(256个GPU)与Summit system,64个Node(384个GPU)
4.1.1 Result for Lassen

Lassen系统上All-to-All算法不同节点数量的比较
在8KB的Message Size上有20-30%的改进
在256GPU and 1MB的Meesage Size条件下有39%的性能提升
4.1.2 Result for Summit

Summit系统上All-to-All算法不同节点数量的比较
在Summit系统上有相似的结果,256GPU and 2MB的Message Size有35%的性能提升
4.1.3 AllGather算法比较
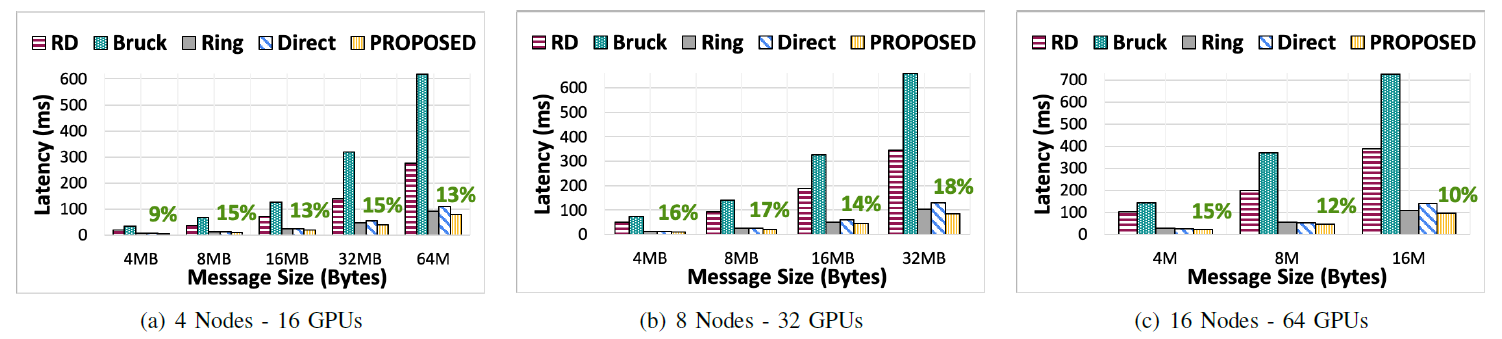
Lassen 系统上 Allgather 算法的不同算法比较
比现存的最好的方法性能提升9~18%
4.2 3D-FFT Application Kernel
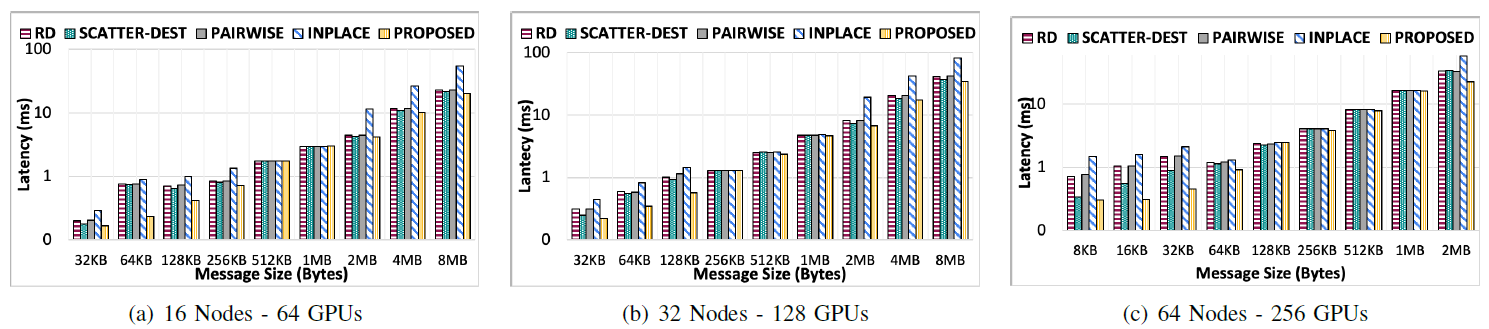
Personalized all-to-all Algorithms for 3D FFT application kernel
测试条件为Lassen System的64, 128, and 256 GPUs
有15~20%的性能提升