WANG W, KHAZRAEE M, ZHONG Z, et al. TopoOpt: Co-optimizing Network Topology and Parallelization Strategy for Distributed Training Jobs [Z]. NSDI. 2023 https://www.usenix.org/conference/nsdi23/presentation/wang-weiyang
论文简介
1. 摘要
本文提出一种新的适用于DNN的直连结构网络T_{OPO}O_{PT},它可以在计算、通信和网络拓扑三个维度上优化分布式训练的过程。我们演示了 AllReduce 流量的可变性,并利用此属性为 DNN 训练作业构建高效的网络拓扑。然后,T_{OPO}O_{PT}使用交替优化技术和名为TotientPerms的群论启发算法来找到最佳网络拓扑和路由计划以及并行化策略。我们构建了一个功能齐全的 12 节点直连原型,具有 100 Gbps 的远程直接内存访问 (RDMA) 转发。对真实分布式训练模型的大规模模拟表明,与类似成本的 Fat-tree 互连相比,TOPOOPT 将 DNN 训练时间减少了高达 3.4 倍。
2. 主要贡献
综合考虑了计算、通信和网络拓扑三个维度的优化策略
分析了MP与AllReduce的流量特征
利用AllReduce的流量可变性优化AllReduce路径
利用交替优化技术和TotientPerms算法来找到最佳网络拓扑
在12个节点的情况下,比传统的胖树网络降低了DNN的3.4倍训练时间
实现方法
1. T_{OPO}O_{PT}架构
假定有n个Server,每个Server有d个接口,每个接口连接一个Optical Seicth,共计需要d个Optical Switch。Optical Switch可以通过配置可以在内部视作直接连接任意两个端口,从而实现任意两个Server之间的直接连接。
论文中提到Server与Optical Switch之间的连接是使用RDMA网卡,并对其进行了修改:原生RDMA网卡会抛弃非本机的数据,修改后支持数据转发和数据中继。
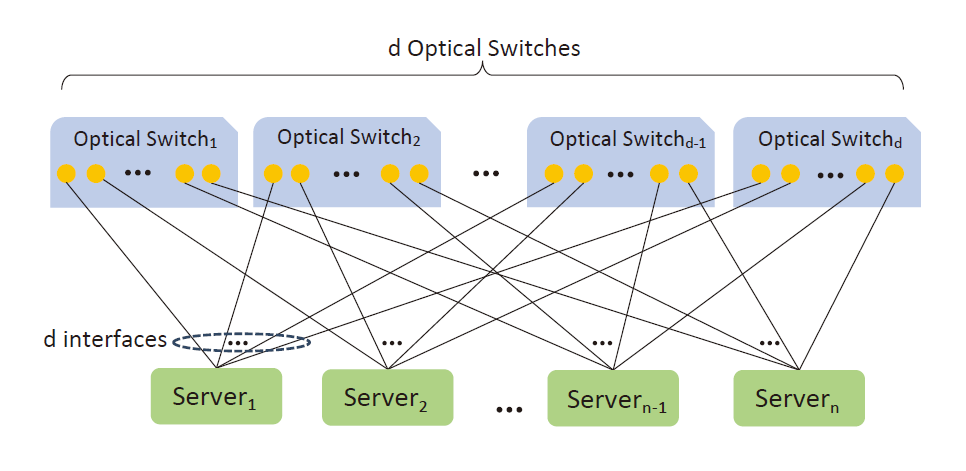
TOPOOPT的网络连接方式
论文中称Server的端口数量d为Server的Degree,它决定着每个Server与其他Server的连接数量,也是 T_{OPO}O_{PT} 算法的一个计算参数。
2. 交替优化策略
问题:
从计算、通信、网络拓扑三个维度对并行计算进行优化会产生一个非常大的搜索空间,导致该优化问题可能无法求得最优解。
通过先优化并行策略再优化网络拓扑的方法可能寻找到局部最优解,但是很难搜索到全局最优解。
解决:
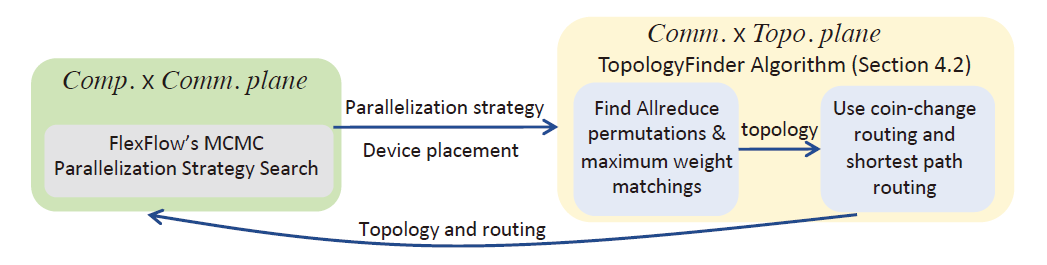
TOPOOPT搜索策略
将网络划分为两个平面:
计算×通信 (Comp.×Comm.)和通信×拓扑 (Comm. × Topo.),通过交替优化策略,在其中一个平面搜索时保持另外一个平面的结果不变。在
计算×通信 (Comp.×Comm.)平面使用FlexFlow的MCMC(Markov Chain Monte Carlo)搜索算法在给定的拓扑结构下寻找最优的并行策略。在
通信×拓扑 (Comm. × Topo.)平面使用T_{OPOLOGY}F_{INDER}算法寻找在给定的并行策略下最优的拓扑结构和布线策略。然后循环迭代多次,直到结果收敛到指定的结果或满足一定的迭代次数。
3. T_{OPOLOGY}F_{INDER}搜索算法
算法的输入参数:
n:Server的数量
d:每个Server的Degree
T_{AllReduce}:基于指定并行策略和设备的AllReduce传输列表
T_{MP}:基于指定并行策略和设备的MP传输列表
算法的输出结果:
G:最优的网络拓扑
R:最优拓扑下的布线规则
算法实现步骤:

4. 不同的传输流量
通过改变网络拓扑结构,使之前的第i个节点传输给第(i+1)\%n个节点的方式变成+3或者+7,通过热力图分析发现,通过网络传输的数据主要可以分为两种:
图中颜色较深的,倾斜的线段为AllReduce传输流量,它会随着网络拓扑的改变发生改变
途中颜色较浅的,水平或垂直分布的为模型并行传输流量,它与网络拓扑的跳数无关
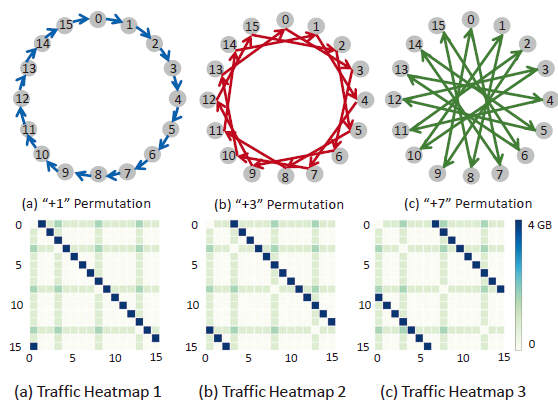
DLRM网络一次迭代的流量热力图
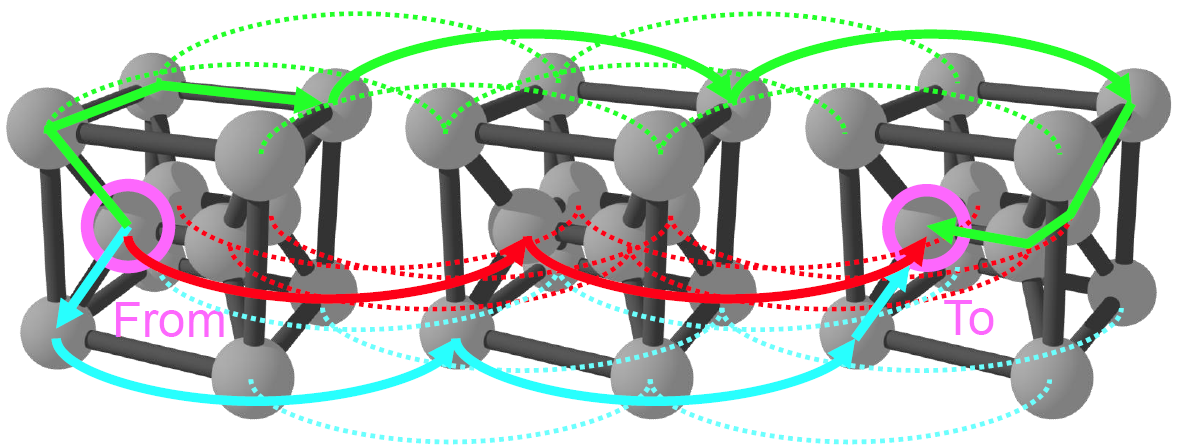
5. 利用AllReduce路径的可变性
在AllReduce的过程中,从A点到B点可以根据网络拓扑的结构不同有多种路径,当存在16个节点,且每个节点的Degree为3时,可以将网络拓扑的结构优化为下图方式,此时一次训练迭代的流量热力图也会发生改变,总传输流量不变的情况下,点对点的通信量下降,可以时点对点的传输效率更高,进而提高训练速度。
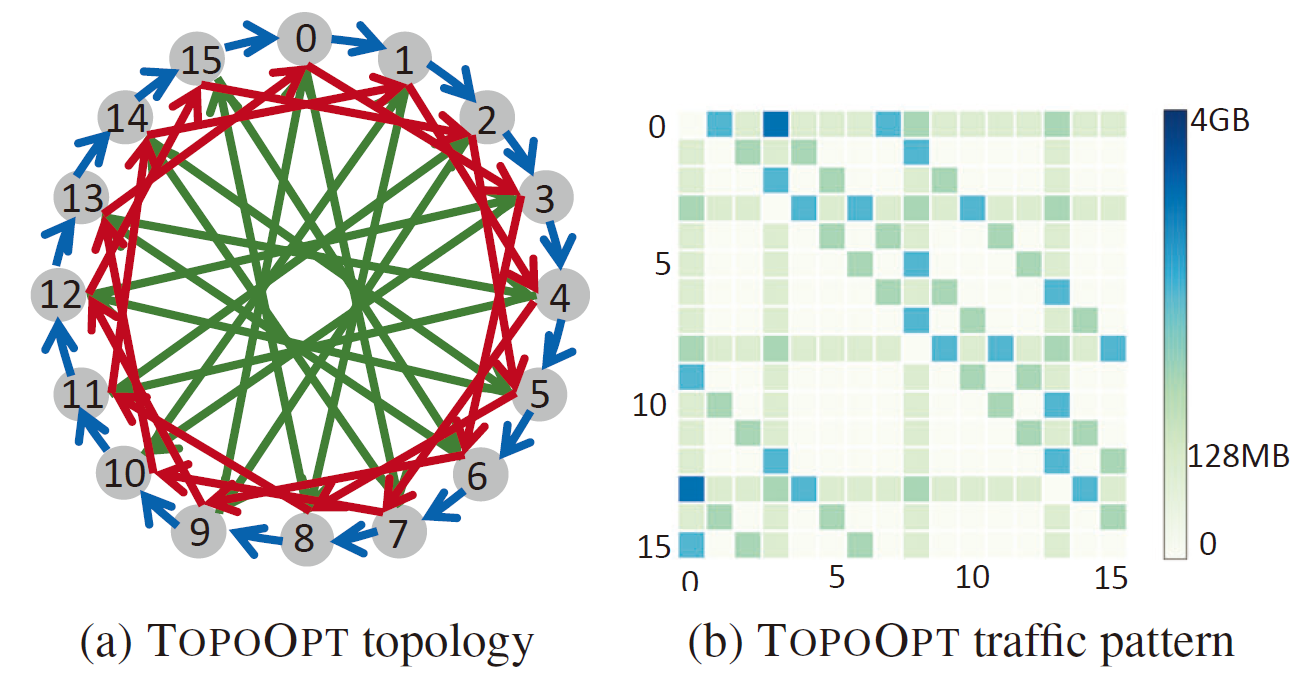
TOPOOPT优化后的拓扑结构和流量热力图
实验结果
原文对进行了大规模的仿真和小规模的实际测试,对带宽、模型、Server数量、Server的Degree、Batch Size等多个参数进行了详细的测试与仿真,请参考原文内容。