参考文献:
Team D, Majumder R, President V, et al. DeepSpeed: Extreme-scale model training for everyone[J]. Microsoft, 2020.
Rajbhandari S, Rasley J, Ruwase O, et al. ZeRO: Memory optimizations Toward Training Trillion Parameter Models[C], 2020. IEEE, 2020-01-01.
Ren J, Rajbhandari S, Aminabadi R Y, et al. ZeRO-Offload: Democratizing Billion-Scale Model Training[J]. arXiv.org, 2021.
Rajbhandari S, Ruwase O, Rasley J, et al. ZeRO-Infinity: Breaking the GPU MemoryWall for Extreme Scale Deep Learning: SC' 21, November 14–19, 2021, St. Louis, MO, USA[C], 2021.
在传统的数据并行(Data Parallelism,DP)过程中,每个节点的都需要保存一份完成的网络模型和对应的参数,这导致了大量的冗余内存占用。当训练的大模型参数足够大时,并行计算节点的内存容量将无法支持一个模型的训练量,这大大的限制了大模型的发展。在并行计算时,为了降低单一节点的内存占用量,可以采用模型并行(Model Parallelism,MP),但MP的方式将会增加大模型网络的搭建工作量。
1. ZeRO
ZeRO是Microsoft提出的一种零冗余优化(Zero Redundancy Optimizer,ZeRO)概念,通过ZeRO技术可以实现大规模的数据并行,且增加的额外网络通信带宽要求是可接受的。
1.1 研究背景
数据并行占用过多内存导致单节点单设备无法容纳完整的大模型网络,从而限制大模型训练的发展。
1.2 实现方法
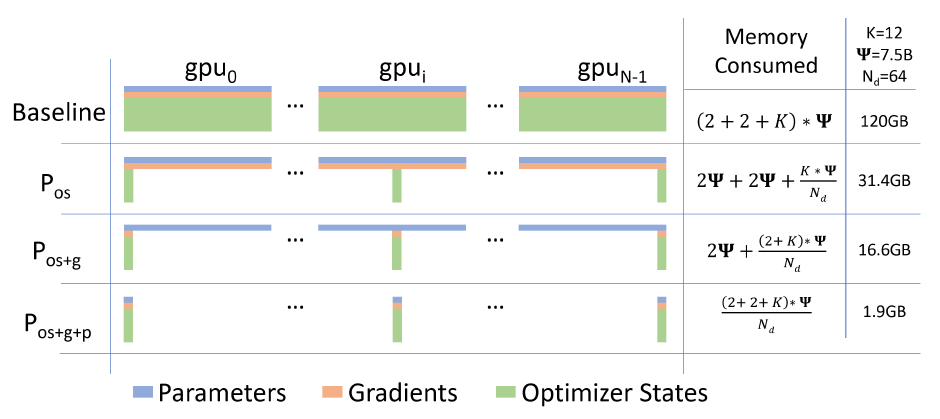
图. 每个GPU上模型消耗的内存使用情况
通过分析发现,数据并行时GPU在某一时间内只会使用到指定网络对应的内存空间,而其他空间的内存可视为无效占用,可以考虑将这些暂时未用到的内存放置在其他位置(其他GPU中),在需要的时候通过网络通信传回使用,使用完成后再更新到其他指定位置;
通过分析大模型训练对内存占用的类型,可以将内存占用分为两部分:Optimizing Model State Memory(ZeRO-DP)和Optimizing Residual State Memory(ZeRO-R)。
通过对ZeRO-DP中的内存类型进行分析,又可以将ZeRO-DP内存的使用分为三部分:Optimizer State Partitioning(P_{os} / ZeRO-1)、Add Gradient Partitioning(P_{os+g} / ZeRO-2)、Add Parameter Partitioning(P_{os+g+p} / ZeRO-3)
通过将ZeRO-DP的数据分布式存储到不同的GPU中可以实现大模型训练对内存容量的要求,如上图所示为ZeRO对每个GPU上的内存占用策略,其中K表示Optimizer States的乘数,\Psi表示模型的参数量,N_d表示并行的设备数量。
ZeRO-R的数据可以使用Offload技术和Recompute技术降低内存开销
训练过程中由于Pytorch自动申请和释放内存造成的内存碎片,采用预分配和内存管理的方法解决
1.3 实验结论
ZeRO-1和ZeRO两个阶段由于在DP时需要必须的All-Reduce操作,因此不会增加额外的通信量
每个Device储存的梯度参数和优化器参数与上下层之间相关,因此无论是否引入ZeRO机制,都需要进行网络通信进行All-Reduce操作
ZeRO-3会增加一部分的额外通信需求,但最多增加1.5x的通信吞吐量
在引入ZeRO之前,每个Device都有一份完整的参数信息,但由于引入了ZeRO机制,当Device需要运算的模型参数不在当前设备上时,则需要从对应设备上获取,因此会增加一部分的通信量。
ZeRO机制理论上可以支持最大1T参数规模的模型训练,但是当模型参数规模达到100B时,或GPU的数量超过256个时,性能有明显的下降。
1.4 实验数据
1.4.1 参数量级的测试
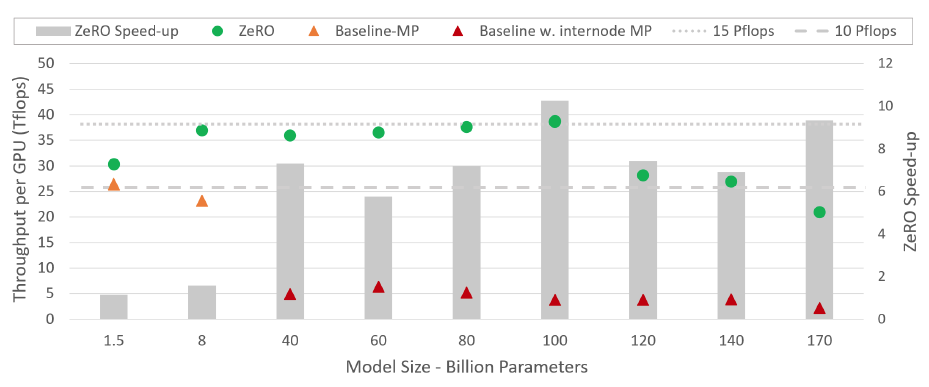
图. 在不同参数量级下的ZeRO的速度提升(对比模型:SOTA MP)
ZeRO的训练总是可以在一个节点内部完成,但是对于大于40B参数的模型SOTA MP必须跨节点才可以完成训练;
当模型参数超过100B规模,则ZeRO的GPU吞吐量将会有所下降,主要原因可能是网络通信造成的瓶颈,同样也会对MP的GPU吞吐量造成影响,因此Speed up并没有明显的下降;
1.4.2 GPU数量的测试
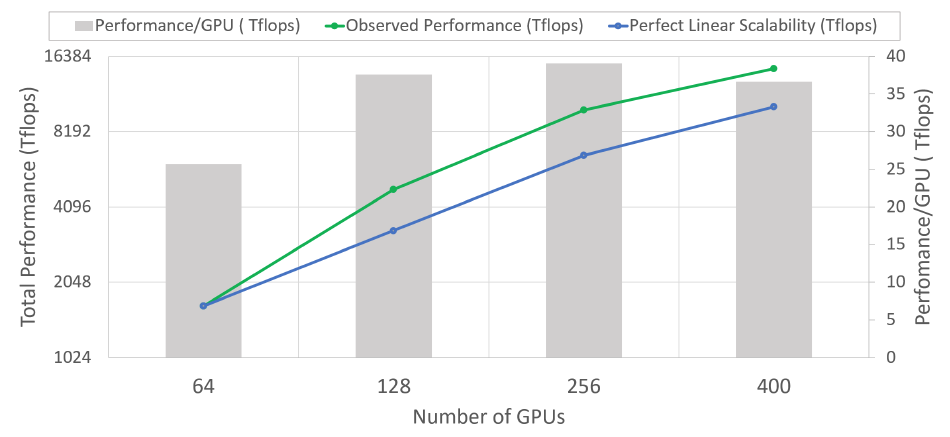
图. 不同GPU数量下使用ZeRO-100训练一个60B参数的模型的算力变化
GPU数量与算力性能之间的超线性关系(绿线为实际性能变化,蓝线为线性增长的曲线,对应左侧坐标轴),由于使用ZeRO会降低单个Device的内存占用,导致运算过程中可以有更多的内存空间可以使用,使得芯片的算力也受影响的有一定层度的增加;
随着GPU数量的增加,当GPU超过256个时,单个GPU的算力性能有所下降,预计也是受网络通信带宽的影响导致的算力下降。
2. ZeRO-Offload
2.1 研究背景
在大模型训练时,内存容量很容易成为训练的瓶颈,即便是使用ZeRO机制将DP的内存拆分存储到不同的GPU上也难以应对继续增长的内存需求,但相对于GPU内存(显存)来说,CPU内存具有更低廉的价格更大的容量,将一部分显存消耗的压力释放到内存上成为了解决内存瓶颈的关键26。
2.2 实现方法
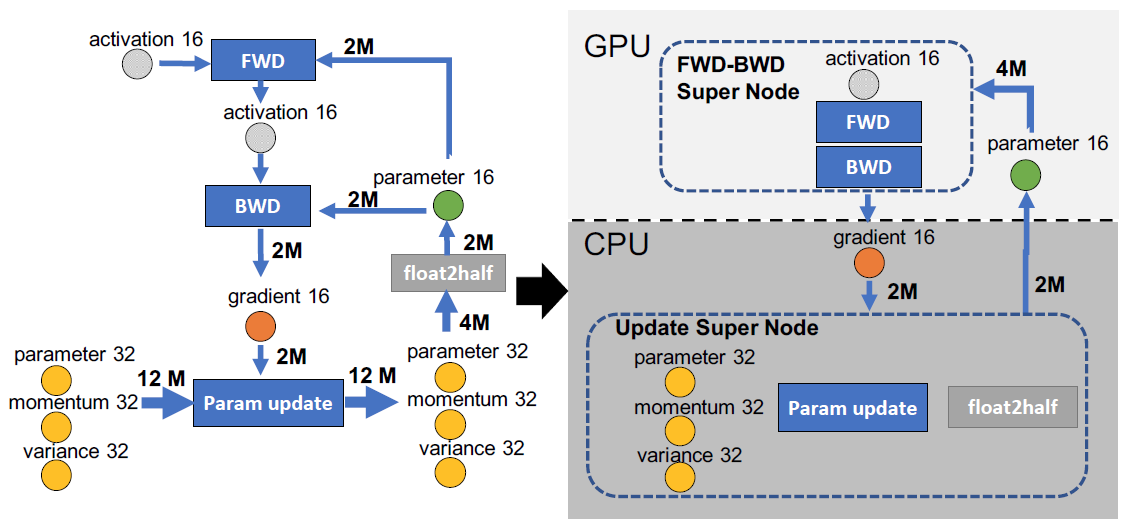
图. 全链接网络的数据流
ZeRO-Offload主要针对Model State(Parameters、Gradients、Optimizer State)所占用的内存空间进行卸载,针对例如Activation所占用的内存,由于其占比小于Model State,在本文中暂不考虑。
如上图所示为使用Adam进行混合精度训练的全链接神经网络,M表示模型参数的数量,
parameter16一般表示16位参数,例如FP16。parameter16与上次的activation16进行前向传播(FWD)的计算并获取新的activation16,并用于后向传播(BWD)的计算出gradient16,最后在Param Update阶段使用混合精度更新得到新的Model State(由于是混合精度,Parameter还需要进行一次float2half操作降低精度)。由于FWD和BWD的计算大多是矩阵运算,因此可以交由GPU进行计算,而Param Update一般是对参数进行数学运算,也可以放在CPU上进行,同时可以把Model State的值储存在CPU内存中
通过Offload操作,每次运算需要GPU把
gradient16传递给CPU,在CPU完成Param Update后将更新后的parameter16传回GPU,每次收发的数据量为2M
在CPU与GPU进行数据交换的过程中,GPU和CPU可以继续异步的执行计算,实现数据传输与计算的并行
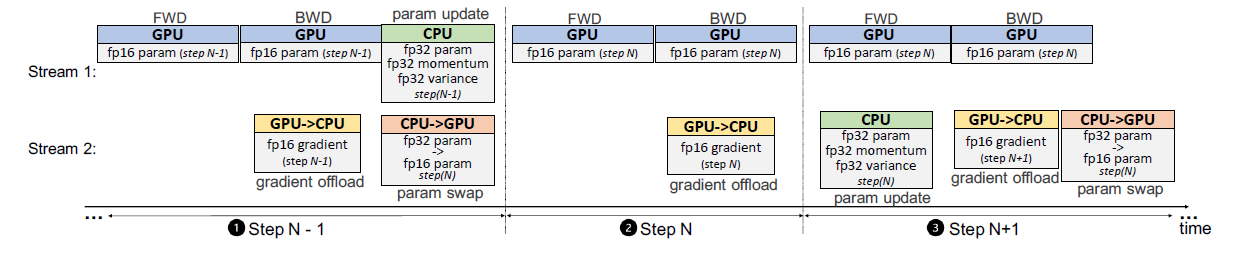
图. ZeRO-Offload的训练时序图
ZeRO-Offload除了内存卸载技术,还继承了ZeRO技术,因此在多GPU条件下依旧会将DP所需的内存坟山到多个设备上进行分布式储存。
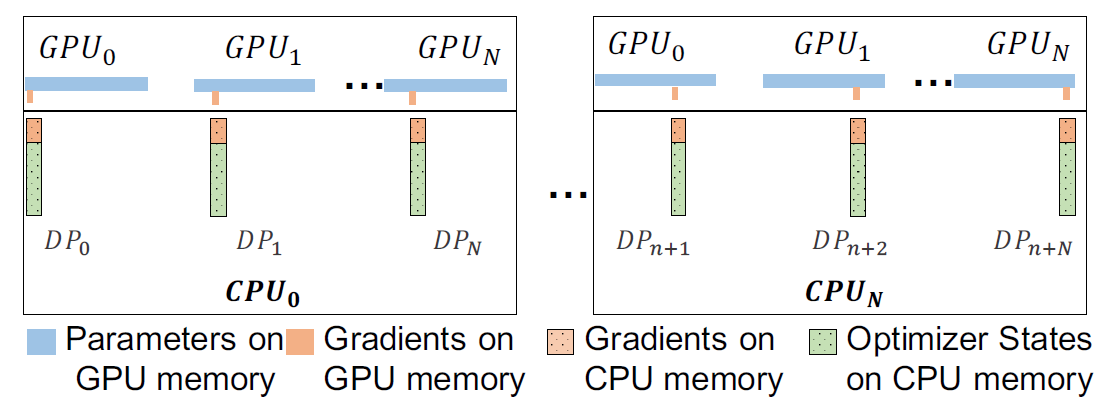
图. 在多个GPU上的ZeRO-Offload策略
2.3 实验结论
ZeRO-Offload能确保CPU与GPU之间的通信量尽可能的小,避免数据交换成为瓶颈,并在最小通信开销条件下实现了最大化的内存节省
ZeRO-Offload会将一部分计算量和内存压力释放到CPU上,但与GPU相比,CPU的计算量要少几个数量级,以防止CPU成为计算瓶颈
由于当前一个节点的配置可能是2个CPU+8个GPU,且CPU还需要负责任务调度等工作,使用CPU协助计算很容易使CPU成为并行计算的瓶颈
由于需要CPU与GPU之间进行数据传输,因此该方法依赖PCIe的带宽,而且为了更好的训练模型,需要一个较大的的Batch Size设置22
2.4 实验数据
2.4.1 不同方法的测试
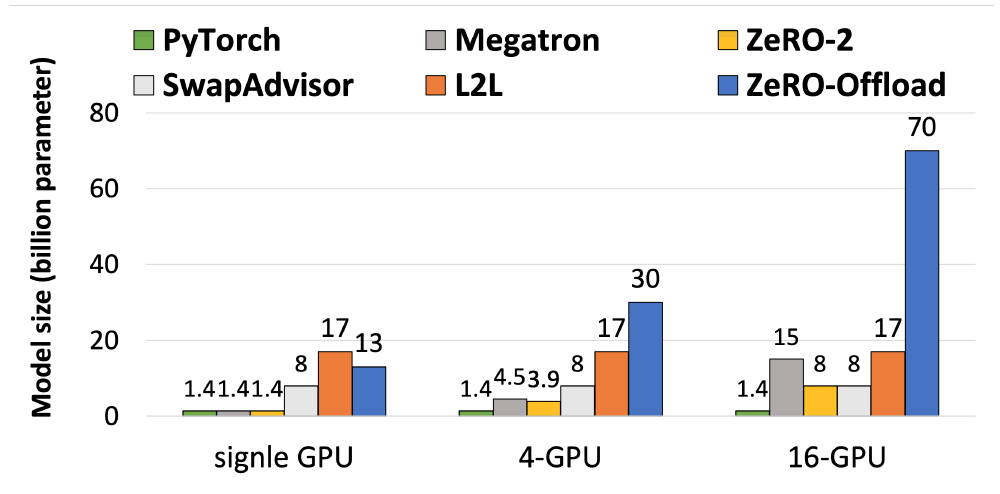
图. 不同方法下可以运行的最大模型的参数量
在单GPU机器上ZeRO-Offload的效果并不是最好的,单机的显存容量限制了可以运行最大模型参数量
在多GPU机器上,由于ZeRO的加持下,将显存压力分散到多个GPU上,可以训练的最大模型参数两具有巨大的提升
2.4.2 参数量级的测试
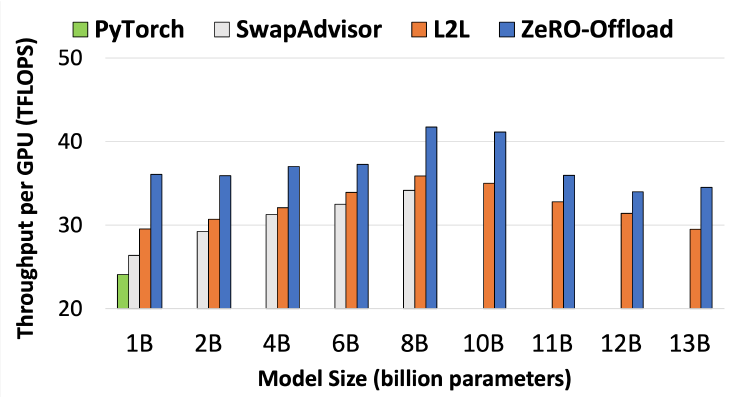
图. 单GPU的算力随着模型尺寸的增加变换
ZeRO-Offload在全部的模型尺寸上效果都优于对比的其他方法
当模型的参数两超过8B时,几乎所有的并行方法效率都有所下降,ZeRO-Offload下降的原因可能是内存占用增加导致效率下降
2.4.3 GPU数量的测试
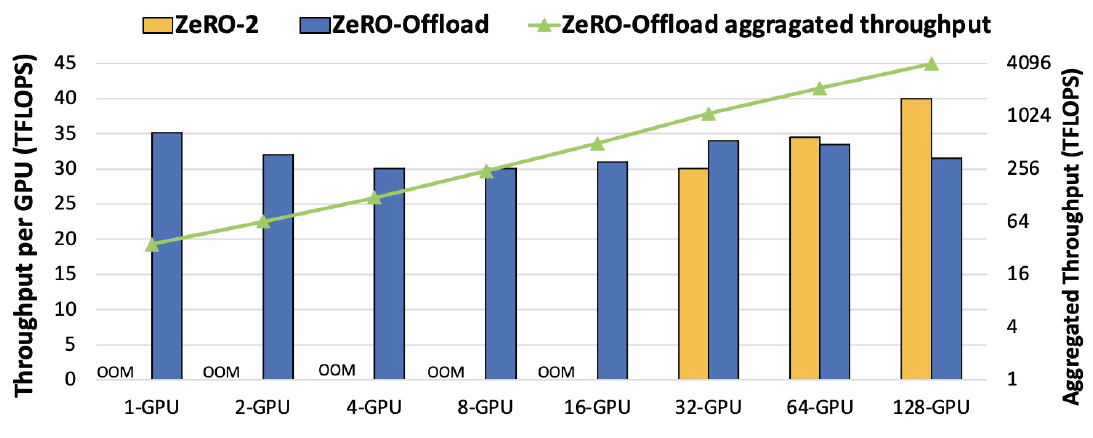
图. 在10B参数的GPT-2模型下不同GPU数量上的表现
ZeRO-Offload最小支持到1-GPU即可运行10B参数的模型,但是ZeRO-2至少需要32个GPU才能运行10B参数规模的大模型
GPU的增长与整体算力的增长基本呈线性关系
ZeRO-Offload在多张GPU上算力表现几乎相同(30-35TFLOPS)
3. ZeRO-Infinity
3.1 研究背景
GPU显存的容量极大的限制了大模型的训练,近三年来模型的参数量级增长了1000倍,但GPU内存只增长了5倍,因此解决大模型训练过程中内存不足的问题成为了必要的基础技术22。
即便是使用了ZeRO-Offload技术也无法应对10-100T级别的大模型,为了解决该问题,提出ZeRO-Infinity技术打破内存壁,极大的降低大模型对内存的依赖
3.2 实现方法
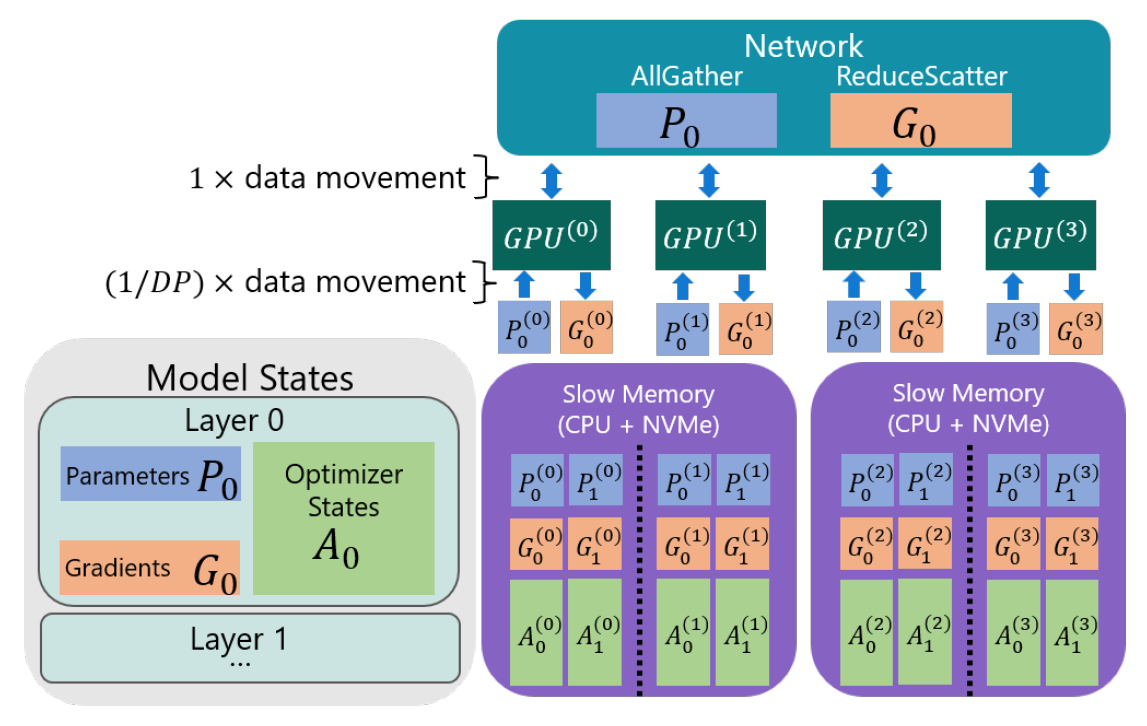
图. 4路DP下的ZeRO-Infinity框架
在不同的GPU之间使用网络进行All-Reduce操作同步参数,GPU内部通过PCIe将数据卸载到CPU内存中
参考ZeRO-Offload技术,单一GPU上的内存占用可以将Model State卸载到CPU内存中
以DGX-2为例,对Parameter和Gradient的传输速度要求是70GB/s,对Optimizer State的传输速度要求是1.5TB/s,对Activation Checkpoint的速度要求是1-4GB/s
数据在CPU内存、GPU内存、NVMe之间的传输和计算可以是并行的
如果要训练的某一层的参数量超过了单一GPU设备的内存容量,可以将该层拆分为多个子序列,并借助ZeRO-Infinity技术按顺序计算这些子序列,以完成较大层的计算
3.3 实验结论
ZeRO-Infinity与ZeRO-Offload不同的是,ZeRO-Infinity可以将Activation Checkpoint卸载到CPU内存上
ZeRO-Infinity巧妙的利用AI训练时不同数据的需求时刻和需求带宽不一样,将数据转存在CPU内存或NVM上,充分利用各个存储介质的优势,ZeRO-Infinity会根据需要将数据卸载到CPU内存或NVMe上,以提高内存容量
ZeRO-Infinity支持一种新的GPU内存优化技术memory-centric tiling,以实现超大的单层网络内存管理,避免超大单层网络所需内存超出GPU最大显存容量
经过ZeRO-Infinity优化,10T模型的Activation Checkpoint可以轻松的放在现在的DGX-2的1.5TB内存上,未来100T模型的Activation Checkpoint也可以放置在新的硬件设备上
3.4 实验数据
3.4.1 GPU数量的测试
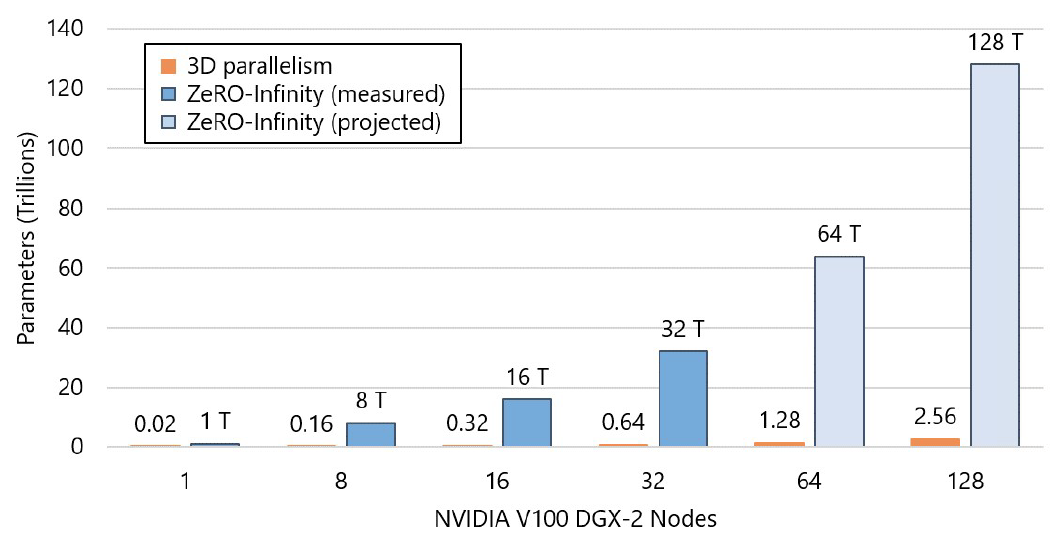
图. ZeRO-Infinity可以训练的模型参数量
ZeRO-Infinity支持32个DGX-2节点(512个GPU)下训练32T级别参数的模型,是当前最新的3D并行框架的50倍
GPU数量与可以训练的参数量几乎是呈线性增长的
预计在128个DGX-2(2048个GPU)上可以实现128T规模的模型运行
3.4.2 参数量级的测试
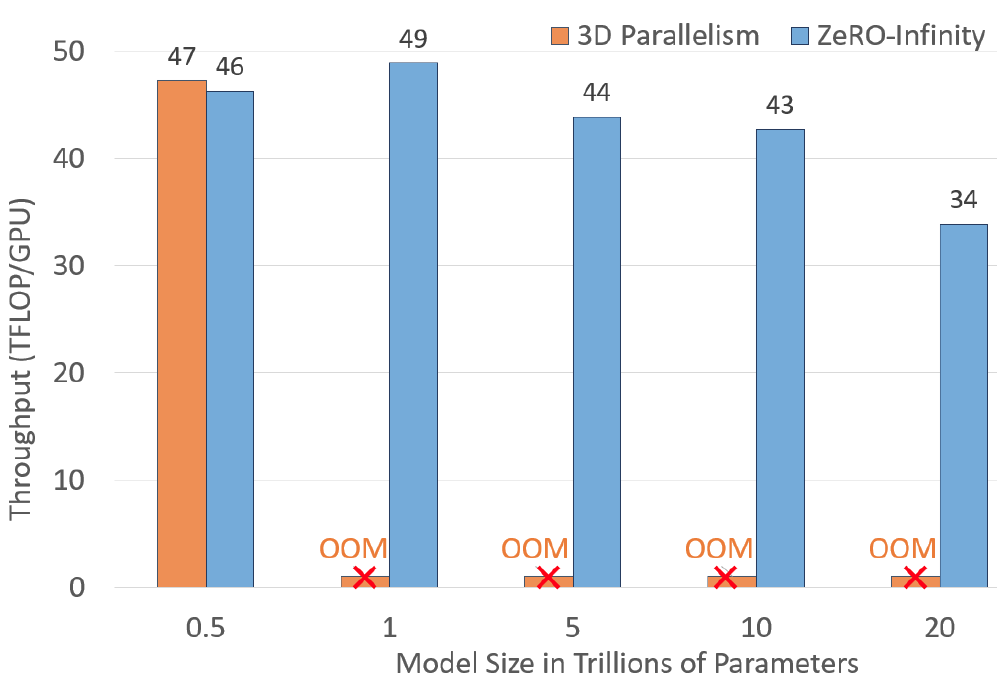
图. 在512个GPU下ZeRO-Infinity与3D Parallelism的结果对比
512个GPU个条件下ZeRO-Infinity支持训练20T参数量的模型,但3D Parallelism只支持到0.5T级别,ZeRO-Infinity是3D Parallelism的50倍
随着模型参数量的增大,ZeRO-Infinity的GPU算力有所下降,可能还是单机的内存使用量增加影响了算力
3.4.3 GPU数量与算力的测试
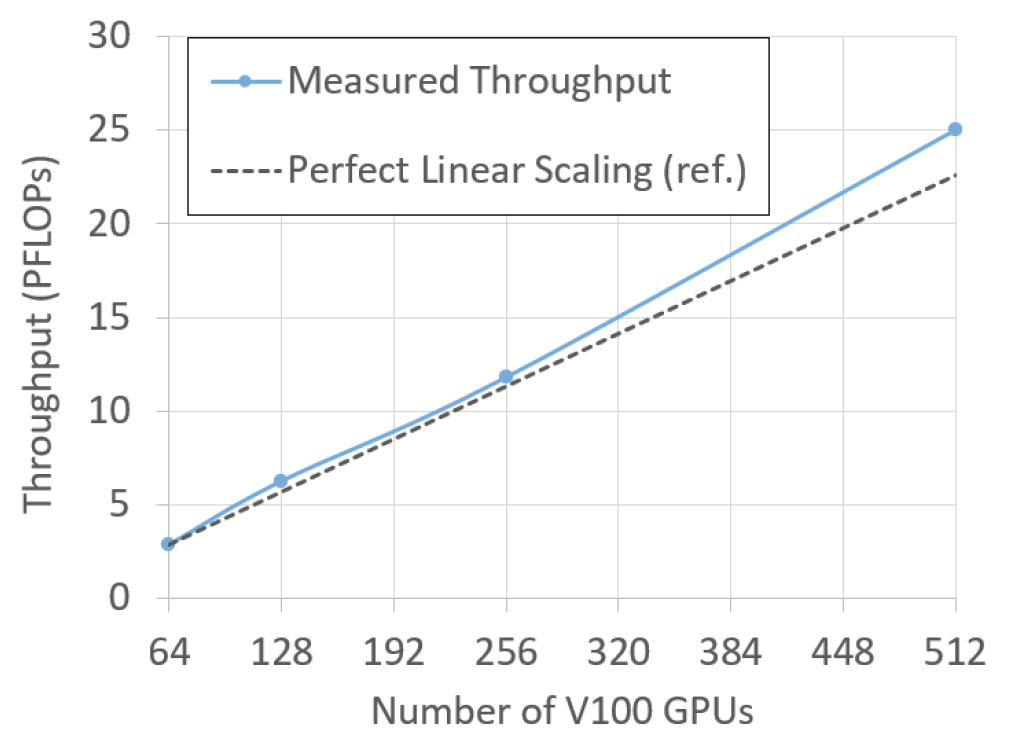
图. GPU数量与算力的关系
ZeRO-Infinity并行框架下,GPU的数量与总算力增长是超线性的,主要原因可能是随着GPU数量增多,每张GPU卡上的内存使用量会有所下降,从而导致每个GPU可用的内存容量更多