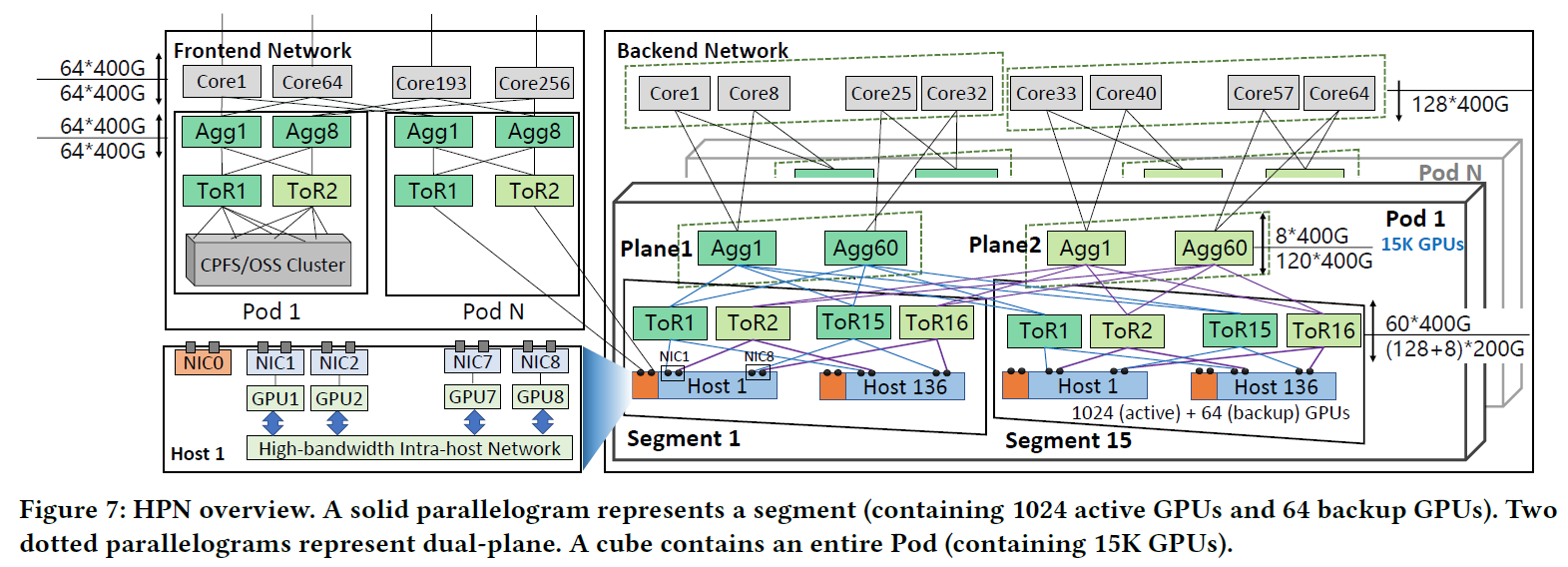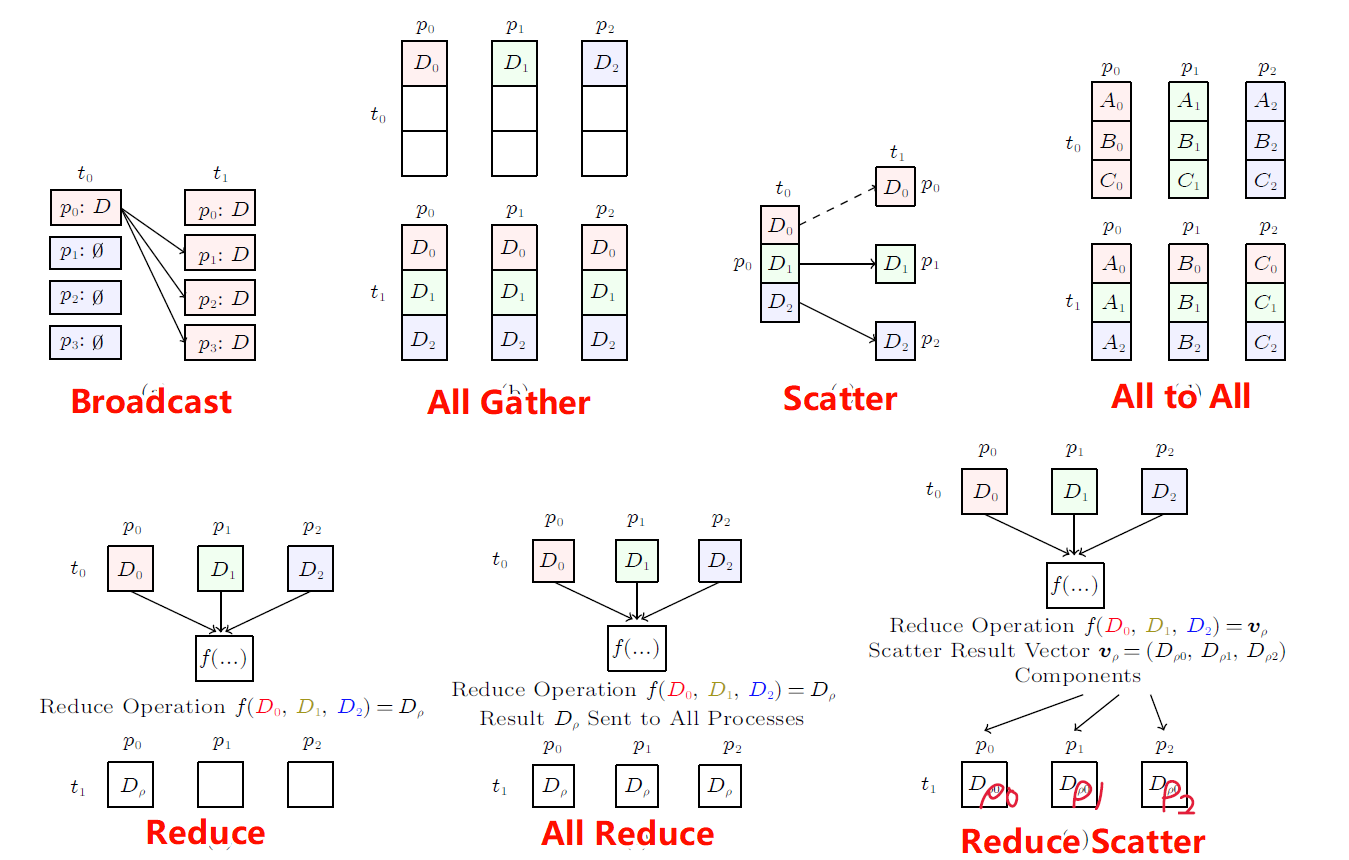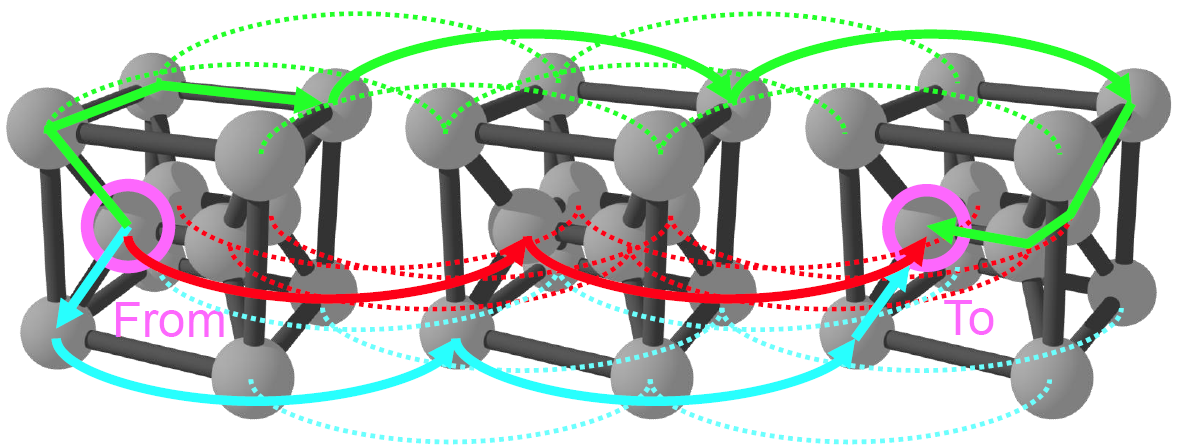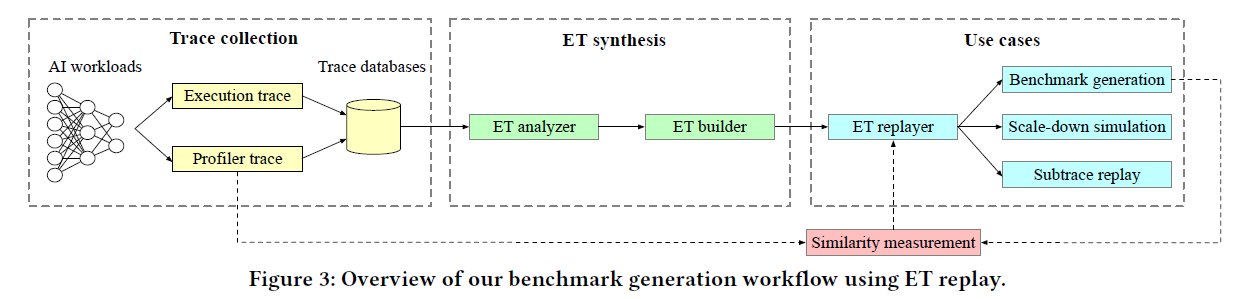
1. Nvidia GPU
参考文献:
HeKun-NVIDIA. CUDA-Programming-Guide-in-Chinese[EB/OL]. https://github.com/HeKun-NVIDIA/CUDA-Programming-Guide-in-Chinese.
Nvidia. Nvidia CUDA编程指南[M]. 1.1. Nvidia, 2008.
1.1 GPU架构
软件层面架构:Nvidia GPU的架构在进行CUDA软件操作时可以抽象为:Thread->Block->Grid三层,通过指定这三个参数可以精确的控制目标运算放在目标的Thread上进行计算。
硬件层面架构:在硬件层可以讲GPU抽象为:SP(Streaming Processor)->SM(Streaming Multiprocessor)->Device三层,基本对应CUDA软件编程层面的Thread->Block->Grid,Nvidia的GPU在指令集上属于是SIMD(Single Instruction Multiple Data)架构,可以实现单条指令在多个数据的并行处理。
集群层面架构:在集群层面,一般按照Host-Device结构划分,其中一个Host可以视作一个由CPU、GPU、内存、硬盘等组成的主机,Device一般特指某一个指定的GPU设备,也就是软件层面的Grid。
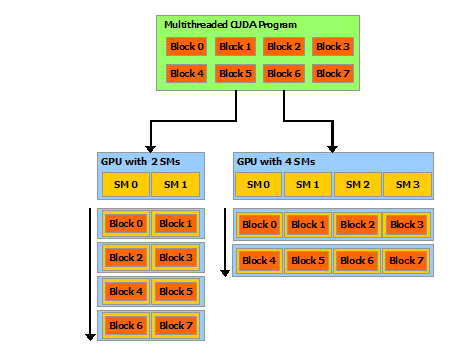
图. Nvidia的GPU架构
A. SP / Thread
GPU上每个SP主要由ALU(逻辑控制单元)与FPU(浮点运算单元)组成,可以进行简单的逻辑运算与浮点运算,每个SP在对应软件层面可以操作的一个Thread,也是开发者可以操作的最小单元,用户可以借助CUDA在Thread上实现SPMD(Single Program Multiple Data)操作。
B. MP / Block
多个Thread组成一个Block,同一个Block上的Thread共享同一块内存(Shared Memory),这种方法可以实现同一个Block上并行的Thread可以并行的对同一块内存中的数据进行操作。
在进行CUDA编程时,开发者可以借助一个SM控制多个Block中的Thread进行运算,SM中还包含一些必要的寄存器、共享内存、L1Cache、Scheduler、SPU、LD/ST单元等。
C. Device / Grid
多个Block一起共同组成一个Grid,也就是硬件层面与集群层面的Device,借助该概念可以实现集群中多个GPU之间的数据传输和并行计算。
1.2 GPU编程
Nvidia的GPU上有多个Thread可以并行的完成矩阵运算,例如在进行通用矩阵乘(GEMM,General matrix multiply)时,不同Thread在共享内存中取出对应位置的数据进行计算,并讲结果重新放置在共享内存中以实现GEMM的并行计算。
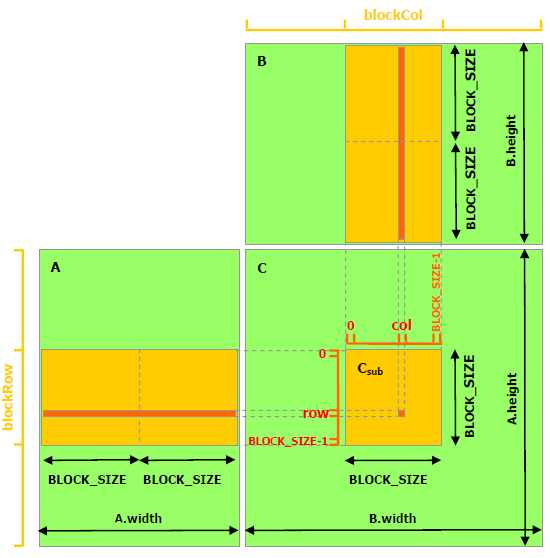
图. 使用共享内存并行计算矩阵乘
在代码层面的实现过程大致如下:
// Host层面的矩阵乘,假定矩阵的维度是BLOCK_SIZE的整数倍
void MatMul(const Matrix A, const Matrix B, Matrix C) {
// 从显存中加载A和B两个矩阵的数据
cudaMalloc(..., size);
cudaMemcpy(..., ..., size, cudaMemcpyHostToDevice);
// 从设备显存中申请储存乘法运算结果的矩阵C
cudaMalloc(&d_C.elements, size);
// 调用内核
MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C); // <<<dimGrid, dimBlock>>>
// 从显存中获取计算结果C
cudaMemcpy(..., ..., size, cudaMemcpyDeviceToHost);
// 释放显存
cudaFree(...);
}
// 调用MatMul()以实现Kernel层的矩阵乘
__global__ void MatMulKernel(Matrix A, Matrix B, Matrix C) { // __global__
// 每个Thread计算矩阵C中的一个元素,并将结果累加到CValue中
float Cvalue = 0;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
for (int e = 0; e < A.width; ++e)
Cvalue += A.elements[row * A.width + e] * B.elements[e * B.width + col];
C.elements[row * C.width + col] = Cvalue;
}2. Huawei NPU
Huawei的NPU设备Ascend 910B相较于Nvidia的GPU做了一些有针对性的优化,同时由于NPU主要针对神经网络训练与推理,因此其在芯片设计架构上与Nvidia的GPU拥有完全不同的设计思路。
2.1 NPU架构
Ascend的芯片架构名称为DaVinci,DaVinci主要针对神经网络的训练和推理进行优化,它的应用场景与GPGPU(General-Purpose Graphics Processing Unit)不同3。其中Ascend中的AI Core中的处理架构图#所示,它包含标量计算单元、向量计算单元、矩阵计算单元、本地数据存储单元Local Memory,以及负责数据搬运的DMA单元等4。

图. DaVinci的AI Core架构
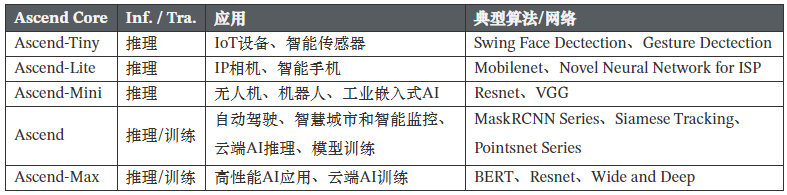
不同版本的Ascend对应的算力资源和应用场景有所不同,通常情况下可以分为以下5个版本的Ascend芯片,其对应的应用场景和常用的算法或网络如表#所示:
表. Ascend分类以及其典型应用
A. TS
为了能够实现计算任务在AI Core上的高效分配和调度,该处理器还特意配备了一个专用CPU作为任务调度器(Task Scheduler,TS),Ascend定制一个CPU负责任务调度,合理利用AI Core中的各个单元的并行任务。
B. MTE
在AI Core中,输入缓冲区之后设置了一个存储转换单元(Memory Transfer Engine,MTE)。这是达芬奇架构的特色之一,主要的目的是为了以极高的效率实现数据格式的转换。Ascend相较于Nvidia的通用GPU其特点就是内存处理上,GPU上通常每次运算需要从DDR上获取数据,但Ascend可以将热数据放在定制的缓存区中,以加快运算效率。
MTE的核心是双Buffer机制,在运算的过程中是应用DMA搬运数据到指定的内存或缓存中。
C. 矩阵计算单元
达芬奇架构在AI Core中特意设计了矩阵计算单元作为昇腾AI处理器的核心计 算模块,意图高效解决矩阵计算的瓶颈问题。
Ascend内置一个16x16的矩阵运算模块,针对16x16矩阵的乘加运算进行硬件优化。
当待运算的矩阵大小超过16x16时,需要将矩阵按照16x16大小进行拆分运算,并通过多次矩阵运算求得最终运算结果。
D. 数据通路
达芬奇架构数据通路的特点是多进单出,数据流入AI Core可以通过多条数据通路,可以从外部直接流入矩阵计算单元、输入缓冲区和输出缓冲区中的任何一个,流入路径的方式比较灵活,在软件的控制下由不同数据流水线分别进行管理。而数据输出则必须通过输出缓冲区,最终才能输出到核外存储系统中。
Ascend为了AI计算差异性定制NPU的内部组成结构。
从计算体系结构到储存结构、数据流向、流程控制等完全不同,在一定程度上不具有可比性。
E. 资源利用率
对于昇腾AI处理器来说,合理设计数据 存储和传输结构对于系统的最终运行性能至关重要。不合理的设计往往成为系统性能瓶颈,从而白白浪费片上海量的计算资源。
GPU、NPU、TPU等AI计算芯片的核心发展方向为合理利用全部的片上资源(计算资源、储存资源等)以提高算力和能耗比
2.2 NPU编程
Ascend C编程范式是一种流水线式的编程范式,把算子核内的处理程序,分成多个流水任务,通过队列(Queue)完成任务间通信和同步,并通过统一的内存管理模块(Pipe)管理任务间通信内存。流水编程范式应用了流水线并行计算方法6。
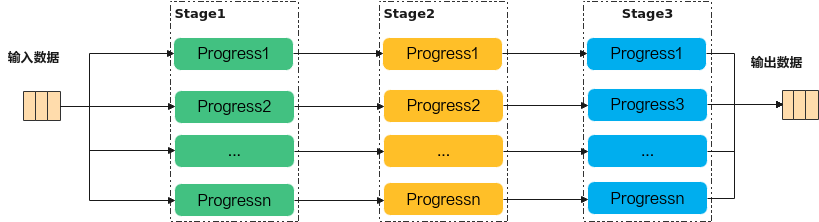
图. Ascend编程流水线方式
Ascend编程的核心思路为将神经网络计算过程中的矩阵计算、向量计算、标量计算等拆分成多个子模块,并使用硬件计算模块对计算过程进行加速,同时配合MTE和TS模块实现边计算边传输,提高计算效率。