参考文献:
Shoeybi M, Patwary M, Puri R, et al. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism[J]. ArXiv, 2020
张量并行(Tensor Parallelism,TP)属于模型并行(Model Parallelism,MP)中的一种,通过对Tensor的拆分,将一次Tensor计算拆分到多台设备上进行并行的计算,并将计算结果最终合并为目标张量。
1. Megatron-LM
Megatron-LM是Nvidia提出的一种Tensor Parallelism方式,它的核心思想是将模型进行纵向分割(假定模型为由下向上的传递方式),Megatron-LM的TP主要针对基于Transformer,通过对Transformer中的Self-Attention和MLP进行拆分并行。
1.1 研究背景
在研究MP技术时,从数学上对矩阵计算的角度上发现针对Transformer可以进行纵向分割,从而在纵向分割上实现并行加速,由于这种方法将一个张量分割为多个张量并行计算,因此该方法属于Tensor Parallelism。
1.2 实现方法
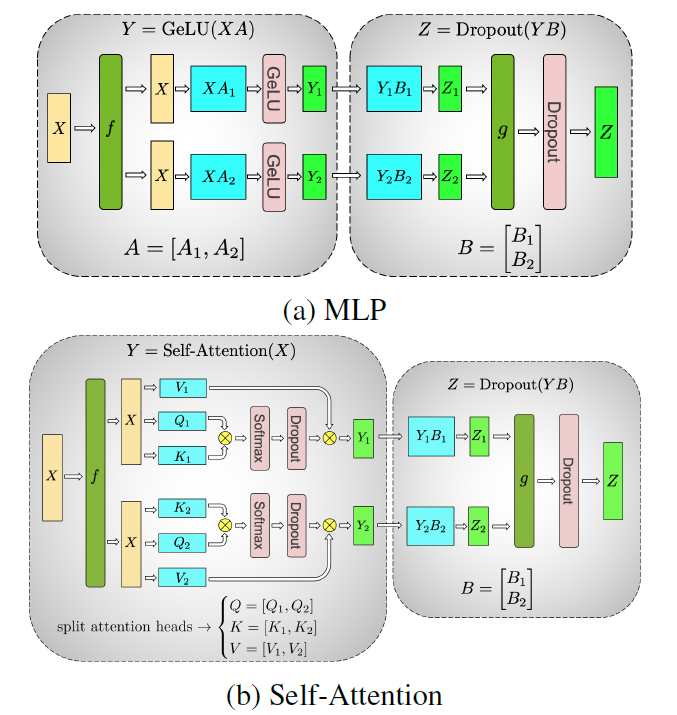
图. Tensor Parallelism对Transformer中两部分的并行过程
针对Transformer中的MLP单元
MLP在并行之前的运算过程可以表示为:Z=Dropout(GeLU(XA) B),其中X为输入数据,Z为输出数据,A和B分别为神经网络的参数
在并行时,可以将A矩阵按照列拆分为A=[A_1, A_2]两部分,并将其分别放置到两个设备中分别对输入的X进行计算,并分别获得结果Y_1=GeLU(X A_1)和Y_2=GeLU(X A_2)
对矩阵B按照行拆分成两部分,并分别放置到两个设备中B=[B_1; B_2]
假设输入的X矩阵的维度为m x n大小的,则可用如下公式描述输入矩阵A
X=\left[ \begin{matrix} x_{1,1} & \cdots & x_{1,n} \\ \vdots & \ddots & \vdots \\ x_{m,1} & \cdots & x_{m,n} \\ \end{matrix} \right] =\left[ \begin{matrix} X_1\\X_2 \end{matrix} \right]假设MLP中的矩阵A的维度为n x k,且定义h=k/2,则定义矩阵A如下:
X=\left[ \begin{matrix} x_{1,1} & \cdots & x_{1,n} \\ \vdots & \ddots & \vdots \\ x_{m,1} & \cdots & x_{m,n} \\ \end{matrix} \right] =\left[ \begin{matrix} X_1\\X_2 \end{matrix} \right]由此可以分别计算出Y_1和Y_2(假定对A_1和A_2拆分后空白位置补0),可表示为:
Y_1=\left[ \begin{matrix} X_1 A_1 & 0 \\ X_2 A_1 & 0 \end{matrix} \right] , Y_2=\left[ \begin{matrix} 0 & X_1 A_2 \\ 0 & X_2 A_2 \end{matrix} \right]GeLU()操作是针对矩阵中的每一个元素分别进行的,这里对矩阵的维度和并行无任何影响,因此暂不考虑GeLU()函数
由以上可以计算得到Z_1和Z_2如下所示:
Z_1=\left[ \begin{matrix} X_1 A_1 B_1 & 0 \\ X_2 A_1 B_1 & 0 \end{matrix} \right] , Z_2=\left[ \begin{matrix} 0 & X_1 A_2 B_2 \\ 0 & X_2 A_2 B_2 \end{matrix} \right]
依照此方法将矩阵A按照列的方式切割为A=[A_1, A_2] 在每一步计算时都可以独立进行,直到得到最终的结果Z_1和Z_2
如果将矩阵A按照行的方式切割为A=[A_1; A_2],则在计算Y_1时需要取出X的每一行与A的每一列,又由于A的每一列都分别储存在两个设备上,因此需要在这个阶段增加通信以完成Y_1和Y_2的计算
Self-Attention模块的并行拆分方法与MLP类似
1.3 实验结论
由于TP的自身特性,每一层Transformer的输出都要进行一次All-Reduce,相比较DP而言,会增加通信量,但是其优点是当Transformer的参数量大到一张GPU放不下时,可以使用TP方法放到多张GPU上训练
没办法进行数据通信并行和数据计算并行,必须要等到数据发送/接收完成后才能继续下一步
以单GPU的39TFLOPS算力(30%硬件峰值性能)为基线,集群的最高算力达到15.1PFLOPS,达到了理论计算峰值的76%
获得了几乎线性的GPU数量与算力提升的关系
1.4 实验数据
1.4.1 GPU数量与算力的关系
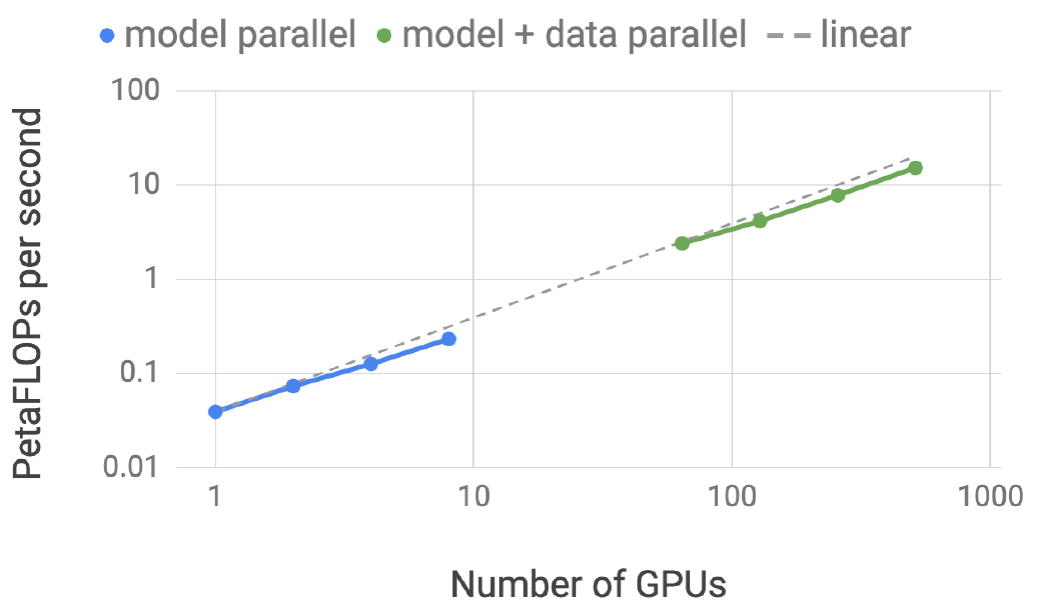
图. 并行的GPU数量与总算力的关系
在1B参数模型上进行GPU训练测试,蓝色曲线为MP(TP)方法,绿色曲线为MP+DP方法,由图表可知,GPU数量的增长与总算力增长的关系几乎是线性的
并行的GPU数量与总算力不呈线性关系的原因是TP过程中通信造成的算力下降
当GPU数量增长到64时,MP+DP的模式的算力高于MP本身,具体原因参考下面的实际实验结果
1.4.2 GPU数量与效率的关系
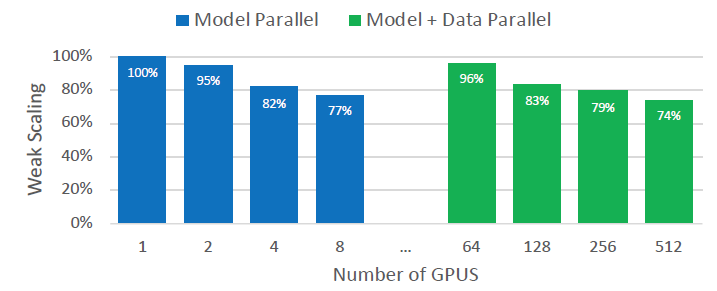
图. 并行的GPU数量与并行效率的关系
蓝色为TP,GPU数量为1时表示不使用TP算法;绿色为TP+DP,GPU数量为64时表示纯DP
当GPU数量为128时表示,每两个GPU之间形成TP并行,64组GPU之间形成DP并行
由于DP可以进行异步,而TP必须等待上一层并行完成All-Reduce后才进行下一步操作,因此当GPU数量为64时,DP+MP的效率略小于单机的MP效率