参考文献:
Huang Y, Cheng Y, Chen D, et al. GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism: 33rd Conference on Neural Information Processing Systems (NeurIPS 2019),[C], Vancouver, Canada, 2018.
Harlap A, Narayanan D, Phanishayee A, et al. PipeDream: Fast and Efficient Pipeline Parallel DNN Training[J]. ArXiv, 2018,abs/1806.03377.
Kim T, Kim H, Yu G, et al. BPipe: Memory-Balanced Pipeline Parallelism for Training Large Language Models: Proceedings of the 40th International Conference on Machine Learning[C], Proceedings of Machine Learning Research, 2023. PMLR.
流水线并行(Pipeline Parallelism,PP)属于模型并行(MP)中的一种,它的核心思想是将模型进行横向分割(假定模型为由下向上的传递方式)。
1. GPipe
神经网络在设计的时候一般按照层或者模块组合构成的,因此可以自然而然的将神经网络按照其自身的网络层分割,平均的将每一层放置到不同的设备上运行以实现并行计算的架构。
1.1 研究背景
由于神经网络是在设计之初就是按照层尽心分割的,每一层都有指定格式的输入和输出,并在层内部进行运算,因此可以按照神经网络的层将一个完整的网络拆分到多个设备上并行的进行计算。
1.2 实现方法
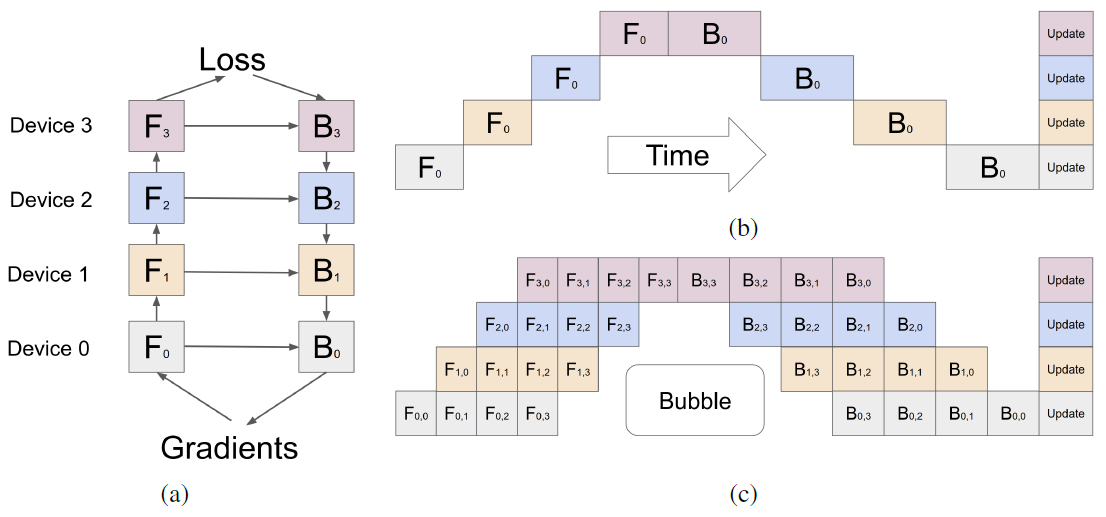
图. GPipe的工作流程
如图(a)所示,假设神经网络一共有4层,并可以均匀的分配到4个设备上,其中前向传播用F_0到F_3表示,后向传播用B_0到B_3表示
如图(b)所示,Device 0完成F_0后Device 1开始进行F_1操作,后向传播时同样需要依赖上一级完成操作后并将参数传递给指定设备,这种方式只是降低了GPU的算力,同一时间只有一个GPU参与运算,并没有实现并行计算
如图(c)所示,将一个Batch分为4个Microbatch,并依次送入流水线中进行计算,如图所示,在第1个时刻只有一个GPU参与运算,在第2个时刻有两个GPU并行参与计算,第4个时刻4个GPU同时参与运算,但是即便将一个Batch分为4个Microbatch,依旧会存在Bubble时间,该时间会导致集群的计算效率下降
假设PP的并行数量为K,Microbatch的数量为M,每个Microbatch的大小为N,模型的层数为L
当M > 4 x K时可以忽略Bubble时间
由于在前向传播计算式需要保留大量的中间变量以便于后续的后向传播计算,通过Recompute机制之后可以在前向传播之后抛弃计算的中间值,在后向传播计算时,再重新计算一次
1.3 实验结论
通过Microbatch和Recompute机制可以实现降低Bubble时间并降低内存消耗
PP的前提是需要假定可以将神经网络均匀的分割到每一个设备上,确保每个设备上的算力消耗是均等的,否则算力较小的设备容易成为短板影响集群的整体性能
后向传播对算力的消耗大约是前向传播对算力消耗的2倍,通过合计的设置Microbatch大小和Recompute机制,可以将Bubble的开销降低到4.1%
如果模型中存在Batch Normalization操作,则需要等待并同步所有节点的运算结果才可以继续进行
1.4 实验数据
1.4.1 耗时占比测试
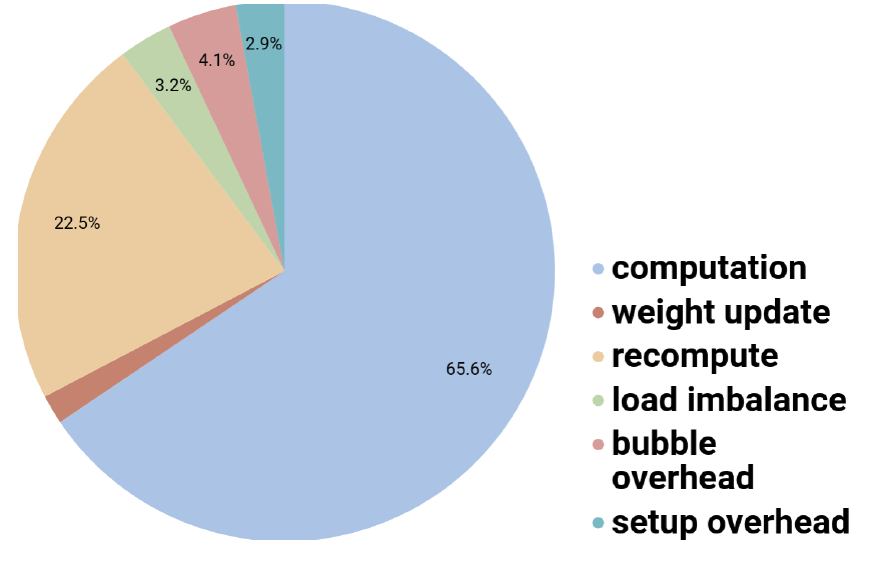
图. 训练过程中每个阶段的耗时占比
有效的计算时间占比超过88%(后向传播占比65.6%,重算占比22.5%)
是不是意味着如果没有重算机制,GPipe的方法实际计算效率并不是很高(65.6%)
由于网络分割出的各个子序列算力不平衡导致的时间占比约3.2%,如果分割的进一步不平衡,则该比例数值可能会进一步增大
1.4.2 内存开销测试
表. 不同模型下并行数量和内存开销的关系
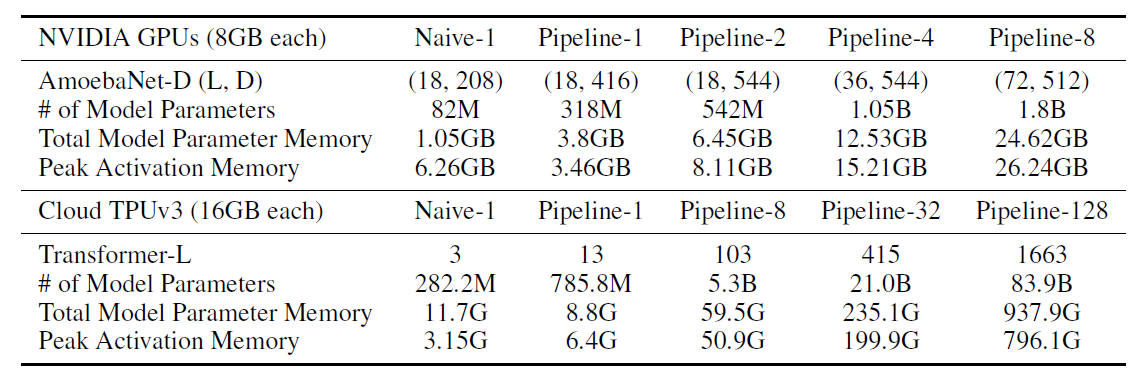
根据正文的相关描述,第一行的NVIDIA GPU应该是Cloud TPU v2
假设只有单卡(Naive-1)的情况下,可以运行82M参数量的AmoebaNet模型,但是如果引入重算机制,在Pipelin-1的条件下,可运行的参数量提升到318M
在TPU v3情况下,Naive-1可运行282.2M的模型,引入重算机制后Pipeline-1可运行785.8M的模型,但是理论上模型的参数量和总的模型参数占用内存应该呈正相关,但是这里总占用内存量却下降了
对于AmoebaNet网络,分割时为了保证每个Pipeline的算力差不多相同,但实际内存占用量缺有差异,从而整体性能可能会收到一定的影响
2. PipeDream
2.1 研究背景
基于Microbatch的GPipe仍然会存在一定的Bubble时间导致总体效率下降,通过重新设计Pipeline的调度算法,实现1F1B的Pipeline调度算法,提高PP的效率。
2.2 实现方法
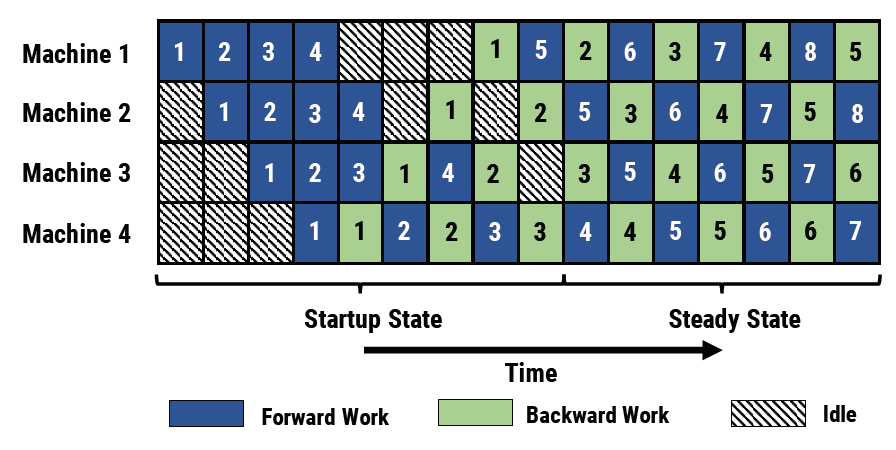
图. 4台设备下的PipeDream方法示意图
GPipe的思想是算完全部Microbatch的FWD后再开始BWD计算,通过增加Microbatch的大小的方法降低Bubble时间,但是Microbatch的尺寸过小可能会导致通信效率降低,从而影响整体性能
PipeDream的优化方案是无需等待全部Microbatch的FWD算完,每算完一次Microbatch的FWD,就立刻开始计算其BWD,通过这种交叉进行的方式可以降低Bubble时间
除了Startup State和最后的阶段,中间的Steady State几乎是没有Bubble时间消耗的
在PP的基础上加上DP和MP方案实现3D并行
2.3 实验结论
在DNN上,降低了DP条件下95%的通信开销,同时实现了通信与计算的异步进行
相比较其他的方案,训练精度更好,训练效果更好
相比较GPipe降低了Bubble时间,提高了GPU的算力
2.4 实验数据
2.4.1 通信开销实验
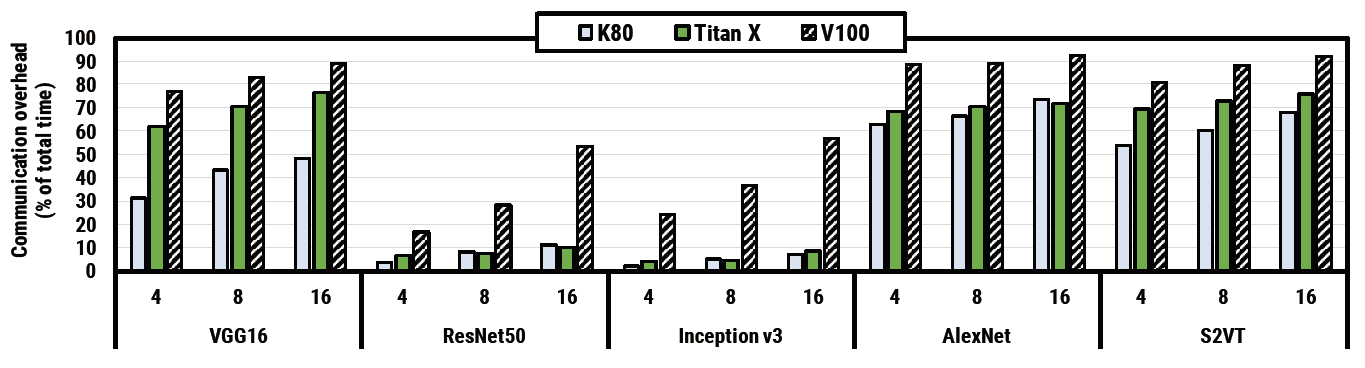
图. 在不同设备,不同模型下的通信开销
算力越高的设备通信开销的占比越大(算力:K80 < Titan X < V100)
并行的机器数量越多,通信开销越大,适用于所有算力的设备与所有模型
2.4.2 训练效率
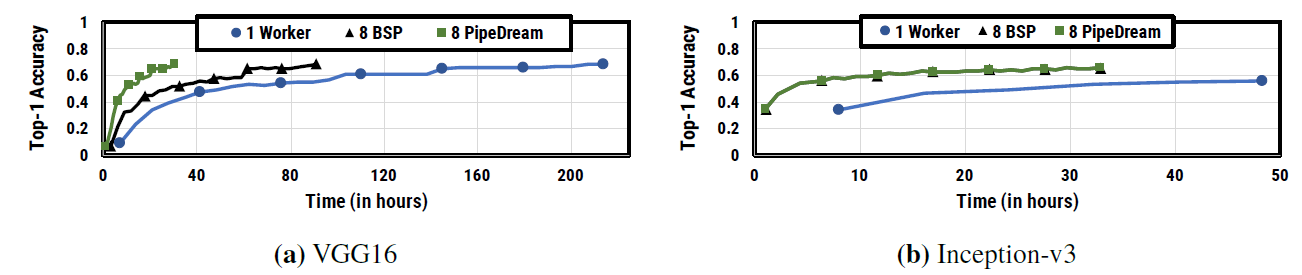 图. 8个设备上的训练时间和训练精度变化
图. 8个设备上的训练时间和训练精度变化
在VGG16和Inception-v3两个模型上PipeDream都能更快的达到目标训练精度
在VGG16上,达到目标精度所消耗的时间相比单机缩短了近70倍
2.4.3 速度提升
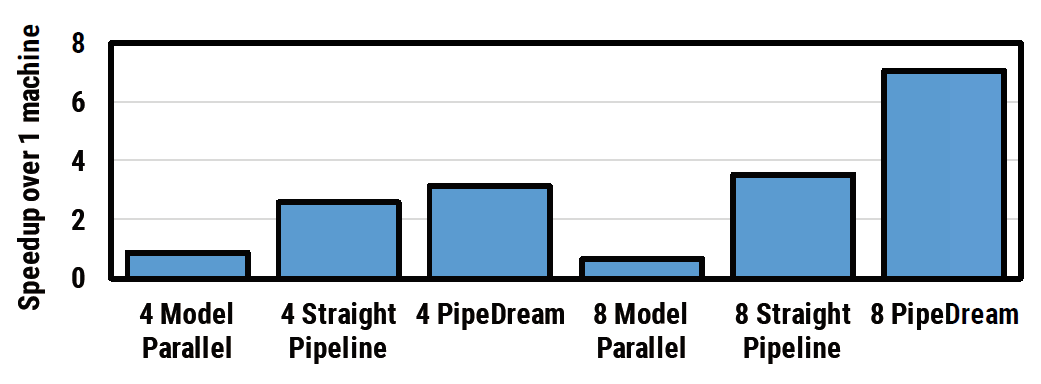
图. VGG16下MP vs. PP vs. PipeDream速度提升
在4个设备和8个设备的情况下,PipeDream的性能提升都是最好的
这里的PipeDream是指在PP的优化的基础上结合DP和MP的方案
3. BPipe
3.1 研究背景
BPipe优化的方向是认为Pipeline方式靠前的Stage(Device/Machine)由于需要储存更多的Activating Memory导致占用的内存更大,从而导致不同的Stage之间内存消耗不平衡。
3.2 实现方法
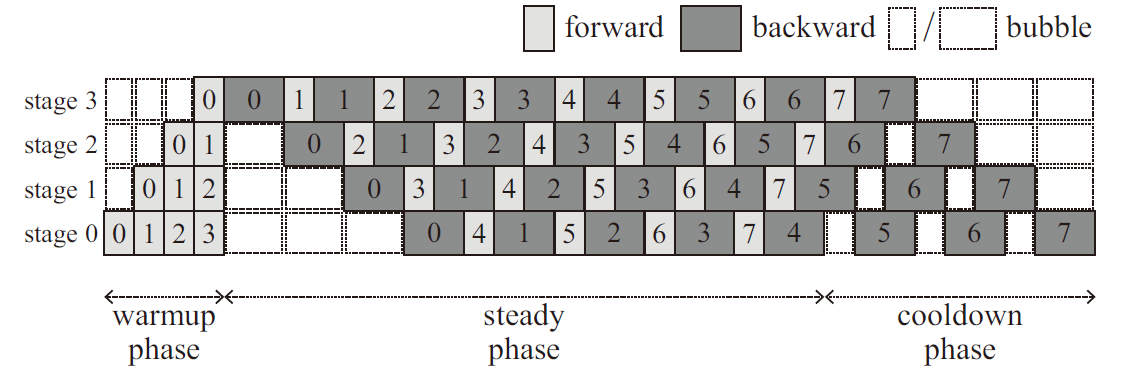
图. 4个Stage 8个Microbatch条件下的BPipe流程图
Stage 0在进行BWD 0之前需要储存FWD 0 ~ FWD3的Activation Memory,但是Stage 3在计算BWD 0之前只需要储存FWD 0的Activation Memory即可,且在计算完BWD 0后即可释放一部分的Activation空间
在后续的计算过程中Stage 0需要储存至少4个FWD的Activation Memory,而Stage 3计算完成后即可释放对应的Activation Memory,因此其只需要储存最多1个FWD的Activation Memory
类似PipeDream的插值Pipeline虽然可以极大的降低Bubble时间的,但是也会导致不同设备之间的内存消耗不一致
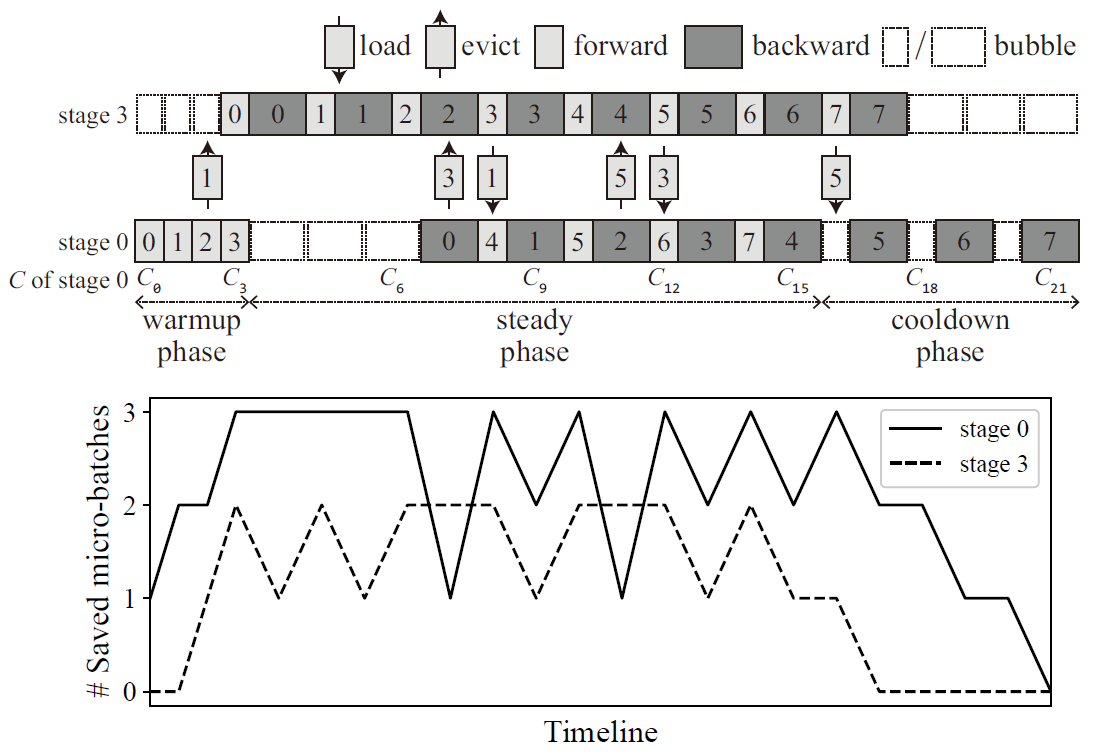
图. Activation Memory平衡策略
如图所示为BPipe的Activation Memory平衡机制,在只有4个Stage的情况下,Stage 0和Stage 1互联交换内存,实现内存平衡
在Stage数量增多时,可以使用NVLink替代传统的Ethernet或InfiniBand网络,实现更高的数据传输带宽

图. 传统使用Ethernet/InfiniBand链接的结构和使用NVLink连接的结构
3.3 实验结论
BPipe的处理方法就是在不同的Stage之间传输内存消耗量,其实有点类似ZeRO的方法
主要优化方法是把Stage0和Stage15(假设有16个Stage)使用高带宽的NVLink连接在一起进行内存共享与内存交换
3.4 实验数据
3.4.1 内存使用量测试
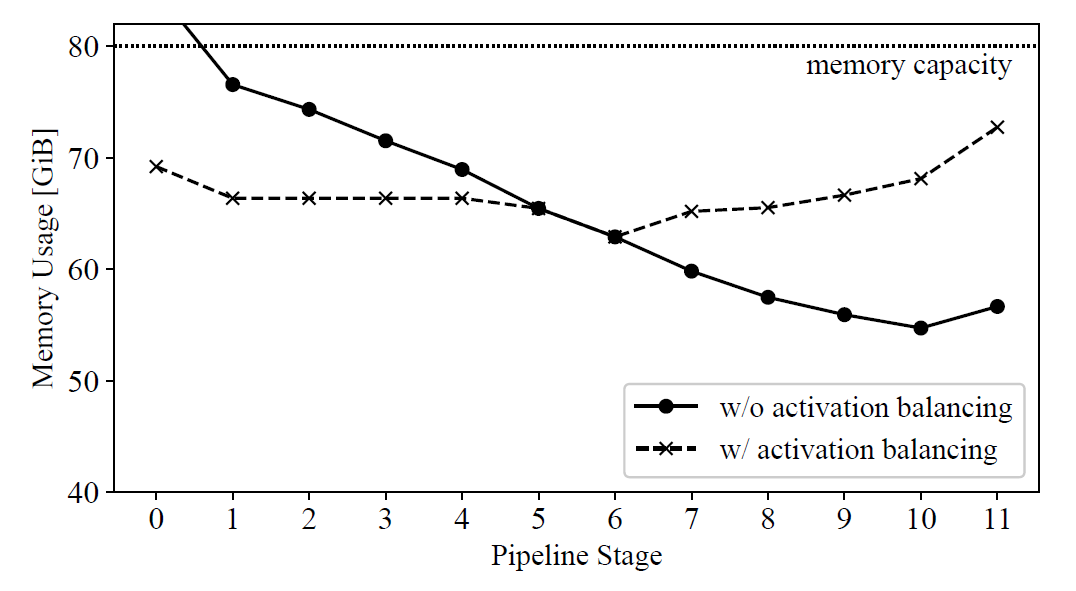
图. PP中每个Stage的内存使用量(GPT-3 134B)
使用BPipe之前Stage 0的内存使用量将会超过80GB,超出了单设备的内容总容量上限