参考文献:
Narayanan D, Shoeybi M, Casper J, et al. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM: SC' 21, November 14-19, 2021, St. Louis, MO, USA[C], 2021. ACM, 2021-01-01.
单一的MP或DP无法硬度继续增长的大模型算力需求,面对成千上万的GPU集群规模增长,结合TP、PP、DP等多种方式组成3D Parallelism的并行方式逐渐成为了主流的并行计算框架。
1. 基于Megatron-LM
1.1 研究背景
单一的DP、TP、PP方法无法满足日益增长的模型参数量,因此提出一种基于多种并行方法的PTD-P并行技术。
1.2 实现方法
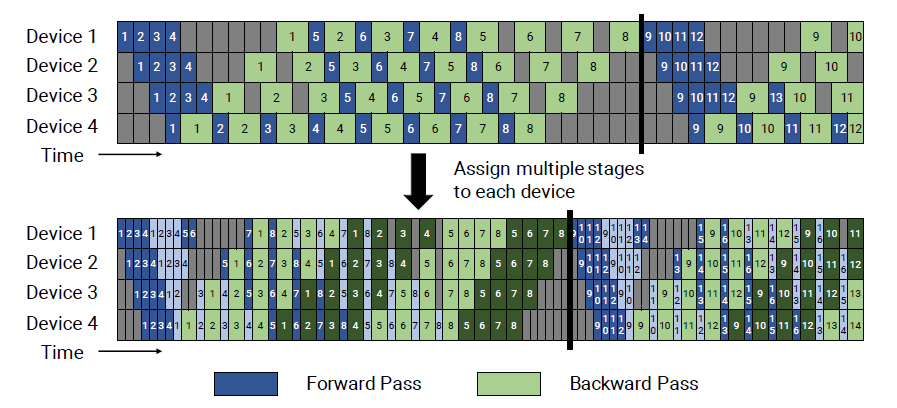
图. 默认的Pipeline调度(上)和插值的Pipeline调度(下)
对每个设备上运行的网络层进行进一步拆分,每个子集称为一个Chunk,在图(下)中用深色和浅色两种颜色表示
假设一共4个Device,每个Device可以分为4层(例如:在Device 1上运行1~4层,Device 2上运行5-8),则可以将每个设备的计算过程分为两个Chunk(每个Chunk需要计算两层网络)例如:Device 1对应1,2,9,10四层,Device 2对应3,4,11,12四层。
以Device 3为例,为什么运行完Chunk 2的Batch2后需要Wait,而不是直接运行Batch 3?只是为了展示插值的概念?
1.3 实验结论
提出一种插值Pipeline调度算法,实现在3072个GPU上训练1T参数的训练,总体算力达到502PFLOPS,单个GPU的算力达到了理论峰值的52%。
相比较ZeRO-3(不带MP),因为减少了通信量,在175B和530B规模的大模型上效果要好70%
插值Pipeline调度算法可以增加计算密集度,但是对通信的开销也会增加
PP在较大的模型上效率更高,效果更好,TP的并行方式会增加不同设备之间的通信量
重算技术只是一个为了平衡内存与算力之间可选的技术,会降低内存消耗,但同时也会增加1/3的算力消耗
高度的MP可能会导致较小的矩阵乘运算,降低GPU的利用率
1.4 实验数据
本文对PTD-P模型中,GPU数量、全局Batch Size、Microbatch Size、Bubble Time、Throughput等多个参量进行多角度多变量讨论
本文还对Checkpoint的加载和保存提出讨论