1. 创建docker
1.1 docker命令
显示全部的镜像:
docker images创建一个容器:
docker run ...<查看1.2节内容>显示全部的容器:
docker ps -a启动一个容器:
docker start <id>停止一个容器:
docker stop <id>进入一个正在运行的程序:
docker exec -it <id> /bin/bash删除一个容器:
docker rm <id>
1.2 创建容器
创建一个docker容器的时候需要同时挂载本地工作目录和相关的程序驱动,因此创建docker容器的命令参数较多,以下为一个创建docker容器命令的基本格式:
docker run -it --ipc=host --name <name> -v <local_path>:<docker_path> \
--workdir=<docker_path> \
--pids-limit 409600 \
--privileged --network=host \
--shm-size=128G \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /etc/bashrc:/etc/bashrc \
-p 223:223 \
-p 224:6006 \
-p 225:8080 \
-p 226:8888 \
-u root \
<image_id> /bin/bash-it:已交互方式运行容器,并分配一个终端-ipc=host:用于docker内部进程与宿主机进程的通信--name<name>:指定要创建的容器的名字-v <local_path>:<docker_path>:挂载本地的<local_path>路径到容器中的<docker_path>路径--workdir=<docker_path>:重定向容器的工作路径到<docker_path>路径--pids-limit 409600:<可省略>对容器内可以运行的进程数量限制--privileged:使容器内的root具有容器外部root的权限--network=host:<删除>指定容器的网络与宿主机相同--shm-size=128G:<可省略>修改共享内存的大小--device=<device>:挂载硬件设备-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:[NPU]挂载NPU驱动-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware:[NPU]挂载Firmware-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/:[NPU]挂载NPU工具包-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi:[NPU]挂载npu-smi命令-v /usr/local/dcmi:/usr/local/dcmi:[NPU]挂载DCMI-v /etc/ascend_install.info:/etc/ascend_install.info:[NPU]挂载安装信息-v /etc/bashrc:/etc/bashrc:添加bash命令行的内容-p 223:223:挂载端口,用于使用ssh直接登录docker容器内部-p 224:6006:挂载端口,将TensorBoard端口映射到宿主-p 225:8080:挂载端口,将MindInsight端口映射到宿主-p 226:8888:挂载端口,将Jupyter端口映射到宿主-u root:以root身份进入容器<image_id>:要创建容器的镜像ID,可通过docker images查看/bin/bash:进入容器后执行的命令,默认进入控制台
在Ascend上使用的镜像信息为:ascendhub.huawei.com/public-ascendhub/all-in-one
完成容器创建后可以通过npu-smi info命令查看NPU状态是否正常,若NPU正常挂载,则会输出NPU的数量、状态等基本信息。
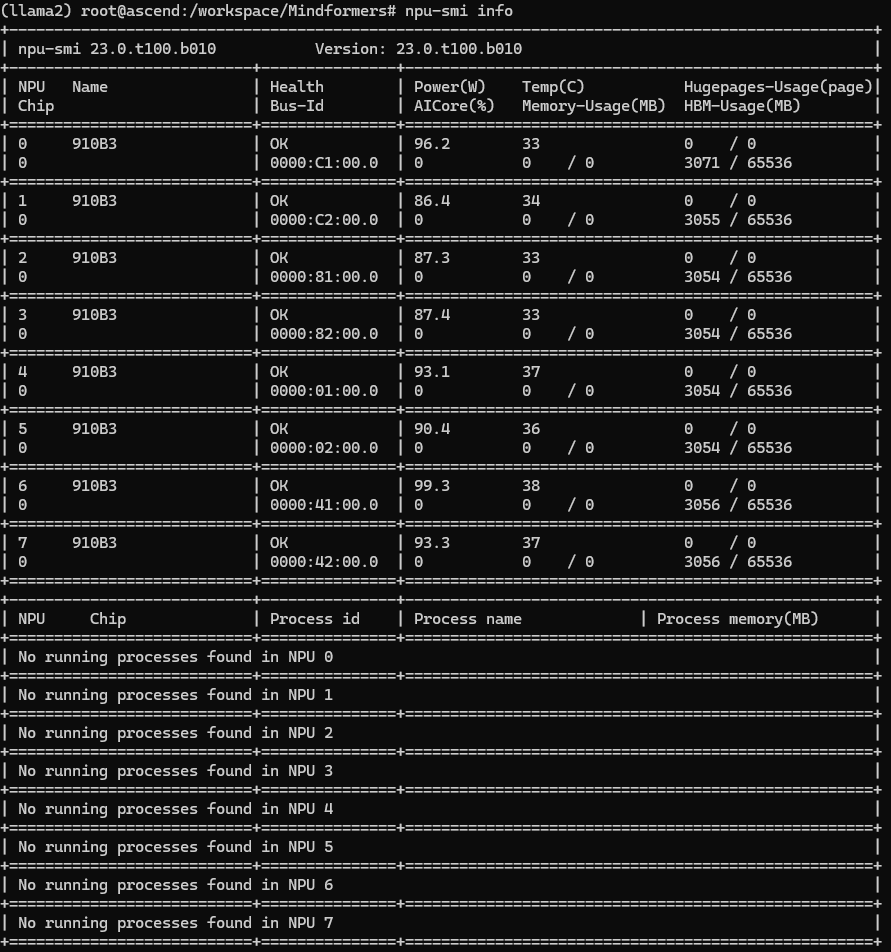
1.3 创建实例
docker run -it --ipc=host --name zhangdx -v ~/workdir:/root \
--workdir=/root \
--privileged \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /etc/bashrc:/etc/bashrc \
-u root \
-p 223:223 \
-p 224:6006 \
-p 225:8080 \
-p 226:8888 \
47f84079ea47 /bin/bash2. 配置SSH
为了使用外部IDE(VSCode或MindStudio等)连接Docker内的编译环境,需要使用SSH将容器内的操作系统通过SSH映射到外部
2.1 安装SSH-Server
需要安装SSH Server,并修改管理员密码,或配置SSH-Key登录的方式登录到Docker内部
# 更新apt
apt update
# 安装SSH-Server和Nano编辑器
apt install -y nano openssh-server2.2 修改SSH配置
使用如下命令修改Docker内部root用户的密码
passwd
# 修改成功后会有如下显示
# passwd: password updated successfully使用nano(也可以使用vi)修改ssh的配置信息
nano /etc/ssh/sshd_config新增
Port 223,这里的端口号应该与创建容器时的一致新增
PermitRootLogin yes新增
PubkeyAuthentication yes新增
ClientAliveInterval 30,设置与客户端之间的心跳包间隔新增
ClientAliveCountMax 10
然后使用如下命令启动ssh并查看ssh的状态
# 启动ssh
service ssh start
# 查看ssh的状态
service ssh status2.3 添加SSH密钥
为了方便后续使用IDE连接docker,建议配置SSH密钥以实现免密登录,使用ssh-keygen命令在本地生成公钥和私钥,并将公钥的内容复制到Docker内
nano ~/.ssh/authorized_keys2.4 添加环境变量
在使用ssh直接连接到docker内时,npu-smi info命令可能出现无法使用的情况,可根据错误提示按照如下方法解决该问题
npu-smi: error while loading shared libraries: libdrvdsmi_host.so: cannot open shared object file: No such file or directory
如果出现该错误是因为相关的环境变量未成功添加到终端,可按照如下方法添加
# 使用nano修改~/.bashrc文件 nano ~/.bashrc # 在最后一行添加如下内容 source /usr/local/Ascend/ascend-toolkit/set_env.shnpu-smi: error while loading shared libraries: libdrvdsmi_host.so: cannot open shared object file: No such file or directory
如果出现该错误是NPU驱动相关的环境变量未添加,可按照如下方法添加
# 查找文件所在的路径 find / -name libdrvdsmi_host.so # 将文件路径添加到环境变量中 export LD_LIBRARY_PATH=/usr/local/Ascend/driver/lib64/driver/:$LD_LIBRARY_PATH
为了方便在每一次打开终端时都可以正常运行npu-smi指令,可以将以上内容添加到~/.bashrc文件中
# 编辑~/.bashrc文件
nano ~/.bashrc添加
source /usr/local/Ascend/ascend-toolkit/set_env.sh添加
source /usr/local/Ascend/driver/bin/setenv.bash添加
export PATH=/usr/local/Ascend/driver/tools/:$PATH添加
export LD_LIBRARY_PATH=/usr/local/Ascend/add-ons/:$LD_LIBRARY_PATH
完成添加后,使用source ~/.bashrc命令重新装载.bashrc文件生效
3. 安装Anaconda
为了解决多种模型和MindSpore对Python版本的需求不一致的问题,安装安装Anaconda创建虚拟Python环境解决该问题。
3.1 下载Anaconda
进入Anaconda的官网获取最新版本的conda安装链接,并如下命令安装Anaconda
下载Anaconda时需要注意对应的版本号和芯片架构类型,例如在Ascend上就是ARM64架构
# 从官网获取下载链接:https://www.anaconda.com/download#downloads
wget https://repo.anaconda.com/archive/Anaconda3-xxx.sh
# 安装Anaconda
bash Anaconda3-xxx.sh
# 刷新环境变量,否则无法启用conda命令
source ~/.bashrc在Ascend上下载的版本为:Anaconda3-2024.02-1-Linux-aarch64.sh
3.2 常见命令
查看全部的环境:
conda env list激活指定环境:
conda activate <name>创建新的环境:
conda create -n <name> python=<3.7.11>删除指定环境:
conda remove -n <name> --all
3.3 创建环境
使用如下命令创建一个名为mindspore的Python环境,后续的所有操作都在该环境下进行
# 创建适用于mindspore的虚拟环境(如果已经存在则无需重复创建)
conda create -n mindspore python=3.7.11
# 进入虚拟环境
conda activate mindspore4. 安装CANN
安装CANN之前需要确保NPU的驱动和固件已经完成安装,此步骤一般宿主机已完成,通过docker挂载到容器内部,可以正常使用
4.1 设备检查
首先使用如下命令确定NPU已成功挂载到服务器上
lspci | grep accelerators在昇腾社区中搜索对应的CANN版本,并下载,选择版本时请选择开发套件toolkit,文件格式为*.run,下载完成后使用FTP或SFTP等工具将文件传输至服务器中
4.2 安装依赖
在安装CANN之前需要安装一些必要的工具包,安装命令如下所示(以Ubuntu系统为例)
# 安装必备组件
apt install -y nano gcc g++ make cmake zlib1g zlib1g-dev openssl libsqlite3-dev libssl-dev libffi-dev unzip pciutils net-tools libblas-dev gfortran libblas3使用python --version检查Python的版本,根据官网的要求,CANN要求的Python版本范围是:python3.7.5~3.7.11、python3.8.0~3.8.11、python3.9.0~3.9.7和python3.10.0~3.10.12,如果Python版本不匹配,则需要使用Anaconda创建对应版本的虚拟环境。
使用pip安装必要的依赖包:
pip install attrs numpy decorator sympy cffi pyyaml pathlib2 psutil protobuf scipy requests absl-py wheel typing_extensions4.3 安装CANN
将下载的*.run文件通过FTP或SFTP等方式上传到服务器上,然后按照如下命令安装CANN开发包
# 修改文件的可执行权限
chmod +x ./Ascend-cann-toolkit_7.0.0_linux-aarch64.run
# 开始安装CANN工具包
./Ascend-cann-toolkit_7.0.0_linux-aarch64.run --install
# 配置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh这里使用的CANN版本为7.0.0,在选择版本时需要与MindSpore版本一致,也需要与Mindformers版本一致,否则将导致不可预料的问题。CANN与MindSpore版本匹配查询网站
5. 安装Mindspore
由于Llama2模型原生使用NCCL(NVIDIA Collective Communications Library)技术,这将导致在Ascend平台上无法正常的运行原生模型,因此需要使用Mindspore Mindformers框架下修改的Llama2模型。
5.1 使用pip安装
Mindspore可以使用pip直接安装,安装过程参考Mindspore,pip安装的Mindspore版本参考如该网站
# 从以下网站获取对应的pip包网址
# https://www.mindspore.cn/versions
wget https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.2.11/MindSpore/unified/aarch64/mindspore-2.2.11-cp37-cp37m-linux_aarch64.whl
# 使用pip安装
pip install mindspore-2.2.11-cp37-cp37m-linux_aarch64.whl这里选择最新版Mindspore(2.2.11版本),硬件平台是Ascend910_Linux-aarch64的Python3.7版本的安装链接
5.2 使用源码安装
不建议使用源码安装Mindspore,仓库内的版本号与CANN、Mindformers等容易发生不兼容问题,但是也可以根据官方教程安装Mindspore
5.3 验证安装结果
使用如下命令验证Mindspore的安装结果
python -c "import mindspore;mindspore.set_context(device_target='Ascend');mindspore.run_check()"
6. 安装Mindformers
6.1 使用pip安装
在官方安装页面找到与Mindspore版本一致的Mindformers安装包,下载并安装即可
# 下载Mindformers
wget https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.2.11/MindFormers/any/mindformers-1.0.0-py3-none-any.whl
# 安装Mindformers
pip install mindformers-1.0.0-py3-none-any.whl6.2 使用源码安装
可以使用git下载Mindformers的源码,然后使用自带的构建工具构建Mindformers环境,但是由于版本依赖问题,不是很推荐使用这种方法,可以使用pip安装对应版本的包
# 下载Mindformers
git clone -b dev https://gitee.com/mindspore/mindformers.git
# 安装Mindformers
cd mindformers
bash build.sh7. 安装Mindinsight
Mindinsight可以帮助分析使用Mindspore构建的应用的性能等信息,使用教程参考官方连接
7.1 使用pip安装
使用pip直接安装Mindinsight即可,但是需要注意其版本应与Mindspore版本一致
# 使用pip安装Mindinsight
pip install mindinsight使用pip的安装时间很长,且中间可能会出现卡死的情况,请耐心等待安装完成
7.2 使用源码安装
参考官方教程从源码编译并安装Mindinsight
7.3 验证安装结果
使用如下命令验证Mindinsight的安装结果
mindinsight start
8. 运行Llama2
Mindformers自带Llama2的模型,可以直接使用API调用Llama2,在缺失权重文件和Token文件时会自动下载对应的缺失文件
8.1 API接口调用
配置单机多卡或多机多卡需要额外的配置服务器的信息,这里先使用单机单卡推理任务验证环境是否配置成功,在任意文件夹创建如下Python文件,并命名为llama2.py
可以根据如下几种API调用方法中的任意一种进行单机单卡推理任务,然后使用python llama2.py命令运行,使用API的接口调用Llama2需要提前使用pip安装Mindformers
A. 基于AutoClass
# llama2.py
import mindspore
from mindformers import AutoConfig, AutoModel, AutoTokenizer
# 指定图模式,指定使用训练卡id
mindspore.set_context(mode=0, device_id=0)
tokenizer = AutoTokenizer.from_pretrained('llama2_7b')
# model的实例化有以下两种方式,选择其中一种进行实例化即可
# 1. 直接根据默认配置实例化
model = AutoModel.from_pretrained('llama2_7b')
# 2. 自定义修改配置后实例化
config = AutoConfig.from_pretrained('llama2_7b')
config.use_past = True # 此处修改默认配置,开启增量推理能够加速推理性能
# config.xxx = xxx # 根据需求自定义修改其余模型配置
model = AutoModel.from_config(config) # 从自定义配置项中实例化模型
inputs = tokenizer("I love Beijing, because")["input_ids"]
# 首次调用model.generate()进行推理将包含图编译时间,推理性能显示不准确,多次重复调用以获取准确的推理性能
outputs = model.generate(inputs, max_new_tokens=30, do_sample=False)
response = tokenizer.decode(outputs)
print(response)
# ['<s>I love Beijing, because it’s a city that is constantly changing. I have been living here for 10 years and I have seen the city change so much.I']B. 基于Pipeline
# llama2.py
import mindspore
from mindformers.pipeline import pipeline
# 指定图模式,指定使用训练卡id
mindspore.set_context(mode=0, device_id=0)
pipeline_task = pipeline("text_generation", model='llama2_7b', max_length=30)
pipeline_result = pipeline_task("I love Beijing, because", do_sample=False)
print(pipeline_result)
# [{'text_generation_text': ['<s>I love Beijing, because it’s a a city that is constantly changing. I have been living here for 10 years and I have']}]8.2 Mindspore推理
使用API的方式调用Llama2推理性能较差,单机单卡在7B模型上大概只有1.3tokens/s的生成速度,通过下载Mindformers源码,并从源码编译运行Llama2模型将获得更快的推理速度,推理速度大概在10tokens/s左右。
无论是基于Generate还是基于Pipeline的推理,文件的前半部分都是按照如下内容编写:
import mindspore as ms
import numpy as np
import os
from mindspore import load_checkpoint, load_param_into_net
from mindspore.train import Model
from mindformers import MindFormerConfig, LlamaConfig, TransformerOpParallelConfig, AutoTokenizer, LlamaForCausalLM, pipeline
from mindformers import init_context, ContextConfig, ParallelContextConfig
from mindformers.tools.utils import str2bool, get_real_rank
from mindformers.trainer.utils import get_last_checkpoint
# 初始化输入内容
inputs = [
"I love Beijing, because",
"LLaMA is a",
"Huawei is a company that",
]
yaml_file="/path/to/yaml_file.yaml"
use_past = False
seq_length = 512
checkpoint_path = "/path/ro/checkpoint.ckpt"
model_type = "llama2_7b"
# 读取配置文件
config = MindFormerConfig(yaml_file)
print(config)
# 初始化环境
tokenizer = AutoTokenizer.from_pretrained(model_type)
init_context(use_parallel=config.use_parallel, context_config=config.context, parallel_config=config.parallel)
model_config = LlamaConfig(**config.model.model_config)
model_config.parallel_config = TransformerOpParallelConfig(**config.parallel_config)
model_config.use_past = use_past
model_config.seq_length = seq_length
# 加载CheckPoint文件
if checkpoint_path and not config.use_parallel:
model_config.checkpoint_name_or_path = checkpoint_path
print(f"config is: {model_config}")
# 构建模型
model = LlamaForCausalLM(model_config)
model.set_train(False)
# 并行运行
if config.use_parallel:
ckpt_path = os.path.join(checkpoint_path, "rank_{}".format(get_real_rank()))
ckpt_path = get_last_checkpoint(ckpt_path)
print("ckpt path: %s", str(ckpt_path))
warm_up_model = Model(model)
warm_up_model.infer_predict_layout(ms.Tensor(np.ones(shape=(1, model_config.seq_length)), ms.int32))
checkpoint_dict = load_checkpoint(ckpt_path)
not_load_network_params = load_param_into_net(model, checkpoint_dict)
print("Network parameters are not loaded: %s", str(not_load_network_params))A. 基于Generate
新建llama2.py文件,将以上内容和以下内容合并为一个文件,并根据实际情况修改python文件中的变量参数,然后直接使用python脚本运行即可。
# 导入上一小节的Python代码
...
# 获取输出
inputs_ids = tokenizer(inputs, max_length=model_config.seq_length, padding="max_length")["input_ids"]
outputs = model.generate(inputs_ids,
max_length=model_config.max_decode_length,
do_sample=model_config.do_sample,
top_k=model_config.top_k,
top_p=model_config.top_p)
for output in outputs:
print(tokenizer.decode(output))B. 基于Pipeline
基于Pipeline的推理调用方法,用法与上一节相似,也需要将公共部分的代码复制到该文件的前半部分。
# 导入上一小节的Python代码
...
# 获取输出
text_generation_pipeline = pipeline(task="text_generation", model=model, tokenizer=tokenizer)
outputs = text_generation_pipeline(inputs,
max_length=model_config.max_decode_length,
do_sample=model_config.do_sample,
top_k=model_config.top_k,
top_p=model_config.top_p)
for output in outputs:
print(output)8.3 性能分析
xxx
附录
一、docker启动命令:
isula run -it --ipc=host --name zhangdx \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \
-v /usr/local/sbin/:/usr/local/sbin/ \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf \
-v /var/log/npu/slog/:/var/log/npu/slog \
-v /var/log/npu/profiling/:/var/log/npu/profiling \
-v /var/log/npu/dump/:/var/log/npu/dump \
-v /var/log/npu/:/usr/slog \
-v /home/zhangdx/:/root/ \
--net=host \
9a2bf88cad61 \
/bin/bash
二、配置容器内的虚拟器apt源:
wget -O /etc/apt/sources.list https://repo.huaweicloud.com/repository/conf/Ubuntu-Ports-bionic.list
apt-get update