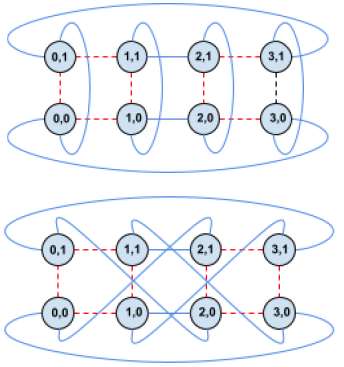
文献阅读《TPU v4: An optically reconfigurable supercomputer for machine learning with hardware support ...》
1. 内容简介 1.1 摘要 为了应对机器学习(ML)模型的创新,生产工作负载发生了翻天覆地的变化。TPU v4 是谷歌第五个特定领域架构(DSA),也是第三台用于此类 ML 模型的超级计算机。光路交换机(OCS)可以动态地重新配置其互连拓扑结构,以提高规模、可用性、利用率、模块化、部署、安全性、功
文献阅读《Impact of RoCE congestion control policies on distributed training of dnns》
1. 内容简介 1.1 摘要 聚合以太网(RoCE)上的 RDMA 协议因其与传统以太网结构的兼容性而对数据中心网络产生了巨大的吸引力。然而,RDMA 协议只有在(几乎)无损网络上才有效,这就强调了拥塞控制在 RoCE 网络中的重要作用。遗憾的是,基于优先级流量控制(PFC)的本地 RoCE 拥塞控
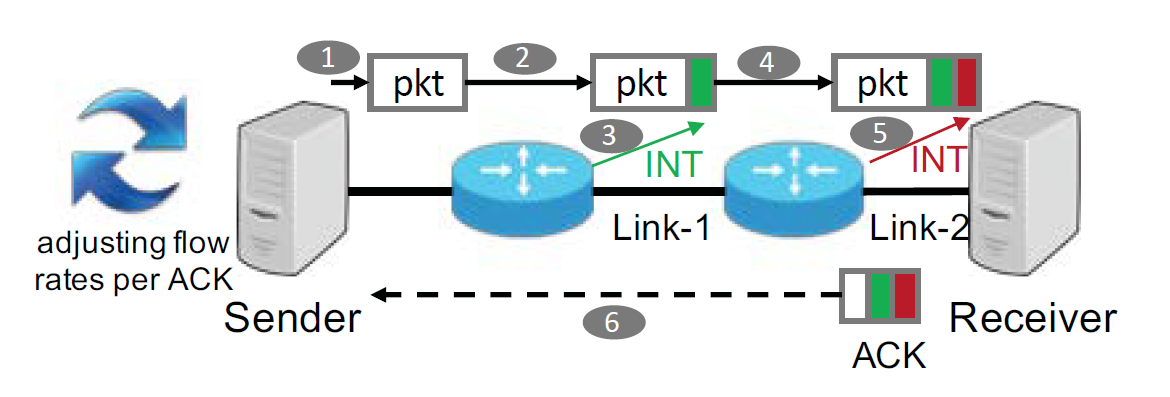
文献阅读《HPCC: high precision congestion control》
1. 内容简介 1.1 摘要 拥塞控制(CC)是高速网络实现超低延迟、高带宽和网络稳定性的关键。根据多年运营大规模高速 RDMA 网络的经验,我们发现现有的高速拥塞控制方案在实现这些目标方面存在固有的局限性。在本文中,我们提出了 HPCC(高精度拥塞控制),一种能同时实现上述三个目标的新型高速拥塞控
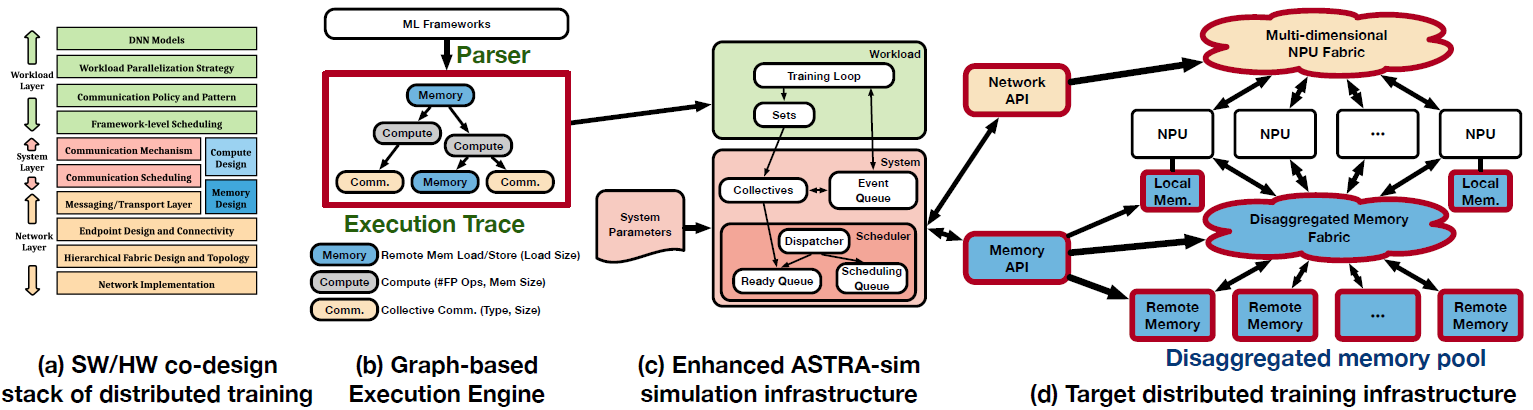
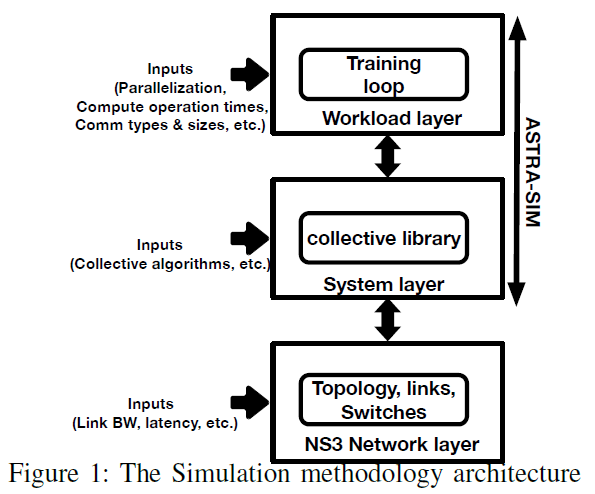
《ASTRA-sim 系列两篇》
《ASTRA-SIM: Enabling SW/HW co-design exploration for distributed DL training platforms》 1. 文章简介 1.1 摘要 现代深度学习系统主要依靠基于高性能加速器(如 TPU、GPU)的硬件平台进行分布式训练。目前的
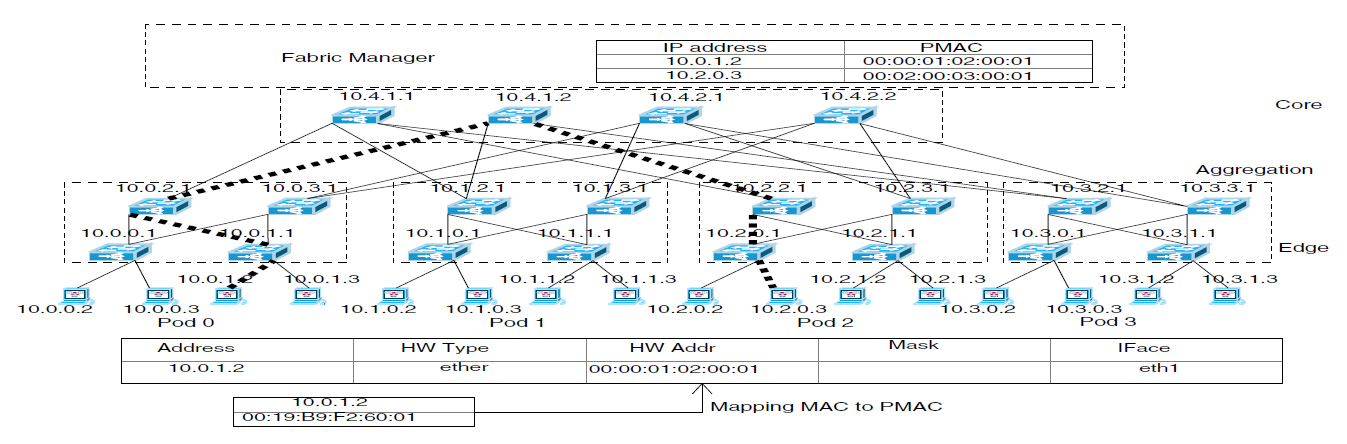
文献阅读《NS3 Simulator for a study of Data Center Networks》
1. 文章简介 1.1 摘要 部署在数据中心网络(DCN)上的应用日益复杂和先进,对 DCN 的新功能和更高性能提出了更高要求。这就产生了许多设计,以应对成本、性能、可靠性、可扩展性、安全性和能源等各种挑战。设计人员经常面临的一个主要挑战是如何实现他们提出的设计或实现现有设计进行比较。虽然原型设计是
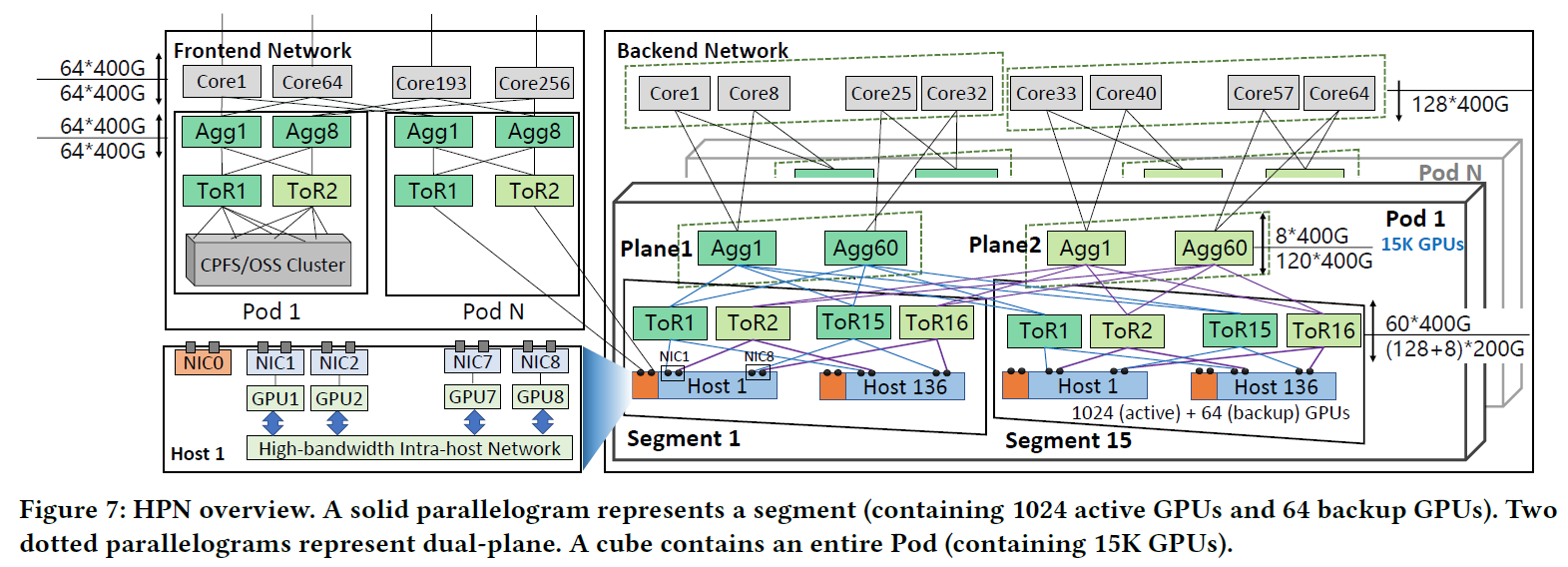
最新文章
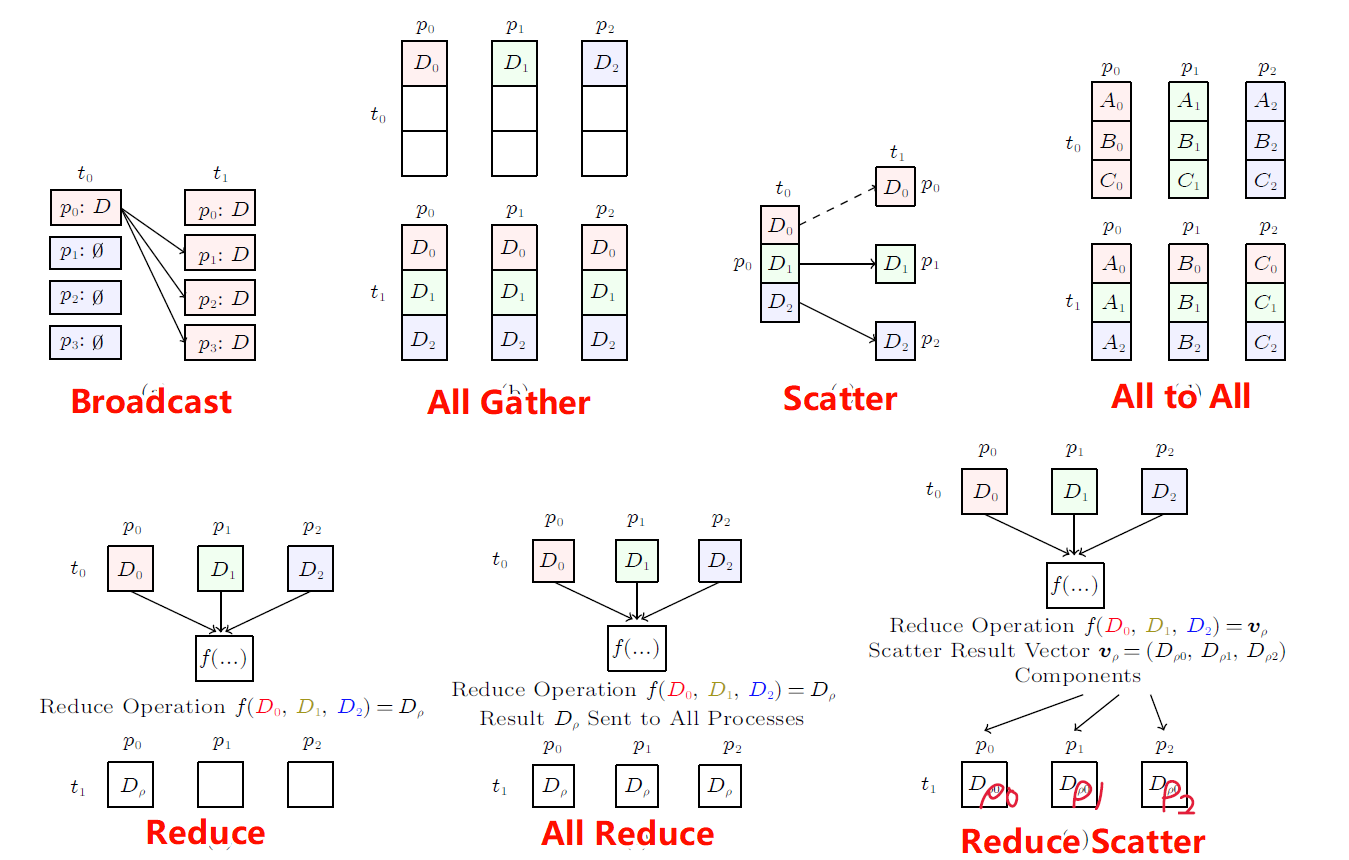
最新文章